To every thing there is a season… and while I still do love the theme I picked out when I originally moved my website to WordPress, even I have to admit that it’s showing its age a little bit. And I don’t just mean in terms of aesthetics. While the theme amazingly has stayed functional through dozens of major WordPress updates, it hasn’t been updated in <cough, cough> years and there were no guarantees it was still secure.
So, without further ado, I present to you my new, updated website appearance.
While I’m doing an announcement blog post, I figure this is also a good time/place to mention that numerous publications that have been clogged up in the pandemic publishing pipeline have finally started to appear in print:
December saw my final publication on the Six Degrees of Francis Baconproject, on the Named Entity Recognition process we used to create our node list, published in the NTMRS studies series.
In July, my co-authored publication on disability in DH will appear in Debates in the Digital Humanities 2023 (I won’t tell you what the year in that title was the CFP went out!)
And last, but never least, By the Numbers, my long-awaited monograph on numeracy and quantitative transformations in early modern England is coming out from Oxford University Press at the end of the year. ETA: It officially comes out January 4, 2024 with pre-orders shipping mid-December 2023, so I hope to be showing off physical copies at AHA 2024 in San Francisco.
So it’s time to say, so long 2010s, old website, and the pre-COVID world. Here’s to the Roaring (20)20s and may things continue to look up from here.
This is a lightly edited and updated version of an invited talk I gave at the DHSI Summer Institute in 2021. It is based on sustainability work we’ve been doing at the Roy Rosenzweig Center for History and New Media (RRCHNM) and while I’m leading the charge, I want to start by acknowledging the contributions of George Mason University (GMU) faculty, staff and graduate students who’ve been integral to this project.
Megan Brett, Digital History Associate (2019-2022)
Laura Crossley, Graduate Research Assistant (2019)
Amanda French, Contractor (2019-2020)
God’s Will Katchoua, Systems Administrator (2019-2022)
Andrew Kierig, Digital Publishing Lead, Mason Publishing (2019-2021)
Joanna Lee, Digital Publishing Lead, Mason Publishing (2022-present)
Dana Meyer, Graduate Research Assistant (2020)
Nathan Sleeter, Research Assistant Professor (2019-present)
Kris Stinson, Graduate Research Assistant (2020)
Tony Trinh, Systems Administrator (2022-present)
Misha Vincour, Contractor (2021-present)
The Metaphor
In traditional analog publishing, there is a moment of transference when the final version of a scholarly book or an article is handed off to the publisher. From the scholar’s point of view, the responsibility of sustaining and preserving their published work now falls on an established pipeline of publishers, printers, distributors, wholesalers, retailers, librarians, and archivists. Hard decisions may eventually have to be made about the fate of a scholar’s so-called backlist of previously-published scholarship—publisher may take books that aren’t selling out of print, and librarians may deaccession unused books when they run out of shelf space—but the scholars is largely insulated from these decision-making processes. As far as they’re concerned, their work can and should live forever.
Digital humanities projects break many traditional scholarly workflows, including those around sustaining and preserving scholarship after it is published—or rather, as is often the case, self-published. As scholars acquire longer and longer backlists of previously-published digital scholarship, many of us will need to grapple with the kinds of issues that publishers and librarians are intimately familiar with. In short, we need to become more intentional about what we are saving, why, and for whom. These questions are at the heart of my sustainability work on several hundred projects created at or hosted by RRCHNM since 1994. And it’s that work I’m going to talk about here.
Over the course of this blog post, I’m going to posit a difference between sustaining and preserving digital projects, examine several ways projects can be sustained or preserved, and consider some of the myriad intellectual, practical, and technical factors that can go into making decisions around project sustainability and preservation.
But first, I want to start out with a hypothesis, that we’ve been using the wrong metaphor. DH projects are not books… they’re cars
Expensive, resource-intensive status symbols with a practical purpose often supplemented by all the latest bells and whistles and attempts by creators to push the envelope of what’s possible. And after you make a big initial investment to get one, there’s only gas and nominal registration fees for the license plates, and they drive along fine for five or seven years—just long enough for that extended warranty the dealer convinced you to buy to expire—then start to break down in increasingly dramatic ways that are increasingly expensive to fix. And at some point that car will either become a classic, worthy of preserving at whatever the cost, or it’ll become too expensive to fix and take a one-way trip to the scrapyard.
Now tell me that doesn’t sound like a DH project, from the big initial grant to build it, to the ongoing hosting costs and annual registration fee for the domain, to the 5-7 year timeline before things start to break and some become classics, and some vanish from the internet.
And if we think about them as cars, rather than books, it can help us begin to readjust our and others’ ideas about how long they should survive and how we might care for them, transform them, and maybe eventually shut them down.
No matter what metaphor we use, DH project creators are generally responsible for the sustainability and preservation of our digital objects, which means we are faced with maintenance and end of life decisions we don’t regularly encounter in physical book publishing situations. Most of us are digital hoarders—we want to keep it all!—but we have to put on the hat of publishers, librarians, and car owners to make hard decisions about where and how to allocate our scarce resources of time and money. This post isn’t going to give you all the answers about how to do that, but it is going to go through how we’ve been approaching this problem at RRCHNM.
The Problem
When I joined RRCHNM in 2018, there was no one looking out for our digital backlist of center projects. By 2019, we had finished a complete turnover of previous directors and systems administrators and our servers had become a repository of orphaned projects and junk:
projects by former center directors and GMU faculty
old course websites for GMU faculty dating back to the 1990s
“friend of Roy” projects, hosted for non-GMU scholars who couldn’t find hosting elsewhere in the early 2000s
projects that never got off the ground
incomplete prototypes for finished contracts
discontinued wikis
random files not connected to any known project
In short, it was not dissimilar to the kinds of junk I find lurking around in the corners of my hard drive when I’m running out of space and looking to delete some old files.
This matters because servers are hacked through old projects. It matters because we have no ability to update or access many old projects. And it matters because when our servers go down or we’re decommissioning servers, we can’t get sites back up again and may not even know the sites existed in the first place.
The Plan
At this point, I did what any good historian-turned-administrator would do… I made a policy, which turned into a workflow, which turned into a tracking spreadsheet. We had over 300 projects on our servers—I say “over” because I don’t know the exact number, we still keep finding ones here or there as we work our way through shutting down and migrating projects to new servers when servers hit end of life and of course new projects spin up almost as fast as we shut old ones down. Speaking of which, I am inserting a plea here to USE SUBDOMAINS NOT SUBFOLDERS because almost all the lost projects and other discoverability issues happen because projects ended up in subfolders of other projects.
Over 200 of the projects we found were flagged in our sustainability triage as needing attention, ranging from projects created in the 1990s to projects just finishing this year (2021). Some were obviously broken. Some looked great until we realized they were running Omeka 0.10beta from 2008. Many had security vulnerabilities or were constantly under attack by hackers (insert obligatory thanks to our systems administrators God’s Will Katchoua and now Tony Trinh who keep us up and running!). While web-based projects are not the be-all, end-all of DH, it is the triage of these projects that I’m going to focus on here.
The core of the policy we generated is recognizing our responsibilities:
to our audiences: people who use and rely on projects, especially K-12 teachers who have incorporated our projects into their curriculum
to our fellow scholars: people who have entrusted their scholarship to us to publish, and who use the projects because they recognize the projects’ intellectual merit and value
to future scholars: people who study history of the DH field
I’m not as worried about “digital dark ages” as some folks may be, as I’m a pre-modern historian and know how much can be done with limited sources! but that doesn’t absolve us of the obligation to save stuff now, it just means it’ll be okay when some or even many of those efforts inevitably fail
to our funders: people we made promises to when they gave us money to create projects
many of those promises turned out to be unrealistic, given what we now know about the longevity of digital projects, but we still have an obligation to fulfill them to the best of our ability
After that, the central part of our workflow is figuring out which pieces of a project are important:
the data (always)
the metadata (yes)
scholarly apparatus around it, if extant (yes)
implicit arguments made by design and interface (some)
opinions differ but I come down on the side of “interface = argument” and so the interface should be saved where possible
code (every once in a while)
bespoke interfaces are interesting; the core installation of WordPress 5.7 not so much
project documentation (in small quantities)
we don’t need every email from the project team but we do need some documentation to understand the purpose and history of projects
Given those responsibilities and our assessment of a project’s importance, the purpose of our tracking spreadsheet is then 1) figuring out what to do with each project and 2) keeping track of them all while we work through the backlist.
Rubber Meets the Road
The first decision we had to make for each project was whether to sustain it or preserve it. Lots of people mean lots of different things by terms, but I use them as “keep running” vs. “keep bits.” A sustained site is one where I can go to the URL and have content sent to my browser and it doesn’t matter to me what is going on under the hood. To visit a preserved site, I may have to jump through more hoops to get to and it may not be in easily readable format anymore, but all the content or code there. To use a book analogy: a sustained site is one that’s on open shelves in the library while a preserved site is one that is in the library’s special collections vault with limited access. To use the car analogy: a sustained car can take you to the grocery store while a preserved car might be up on cinder blocks without its tires.
The 9/11 Digital Archive is a sustained DH project. We’ve moved it from custom code in 2002 to early Omeka versions to the latest versions of Omeka over the years. The data is still there but under the hood looks totally different. World History Commons is also a sustained DH project. The content was migrated from various previous projects created from 1990s onward. Those previous projects were or are in the process of being either shut down or flattened (more on that in a moment) now that their content is searchable in the new interface.
By contrast the ECHO project from early 00s—Exploring and Collecting Archives Online, Science, Technology, and Industry—is a preserved DH project. You can see it in the Wayback Machine and you can find the files in GMU’s institutional repository, but it no longer lives on the RRCHNM servers.
So how do we decide what should be sustained vs. preserved? We have a list of questions we ask ourselves that range from the practical to the scholarly:
whose project is it? does its site belong on our servers or is there somewhere else it can/should be hosted?
is the site being actively updated?
how many people are using the site? how often are they using it?
is this a prestigious project that is often quoted/referenced, regardless of site traffic?
how hard is it going to be to keep the underlying code updated? can we do it in-house or do we have to pay contractors? how long will the update last?
is the site an immediate security risk?
what are the intellectual merits of the overall project?
At the end of the day, our resources are finite and we prioritize our own projects over those that don’t belong to us, especially as places like Reclaim Hosting now make it much easier to self-host a scholarly digital project than 20 years ago. While we do make some exceptions to this rule—primarily for K-12 projects or local historical societies whose sites can be flattened (yes, yes, I will get back to that!) and thus require minimal resources to sustain on our part.
If a site doesn’t belong on our servers, if no one is using it, and if no one on the current RRCHNM team believes in its intellectual merits and wants to take responsibility for it, then the project is transferred to its proper owners and/or preserved.
Otherwise, we are talking about some form of sustainability, depending on the cost, difficulty, and security issues associated with each project.
(Note: I’m excluding ongoing projects from this discussion, because if a project is still being actively developed, it is being sustained as a matter of course.)
Sustainability in Practice
Sustainability generally means one of three things for us: recoding, flattening, and/or reinventing.
First, it can mean actually putting in the time and effort to recode the project as needed. For example, the Google API transitioning behind a paywall broke our Hurricane Digital Memory Bank and Histories of the National Mall projects, which had to be recoded to use Leaflet and Open Street Maps. Obligatory shout-out to Megan Brett and Jim Safley who did most of this work!
However, I want to be SUPER CLEAR that this requires a lot of work and costs money. Drupal 7 and Drupal 8 being depreciated is costing us tens of thousands dollars to get all our Drupal websites updated. And then in another couple of years, we’ll have to update our sites all over again. For some of these sites, updating Drupal or moving to a different content management system (which will also eventually have to be updated) is our only option. They need to have user log-ins and all the other accoutrements of a Drupal website.
For others, though, we can move to our second type of sustainability: flattening the sites (see, I promised we’d get there). Not every project needs to stay online with its original codebase, especially since databases are a security risk and high maintenance. For some sites, the important thing is its content. Anyone who wants to study the history of WordPress site customizations can look at the general codebase—we don’t need to save a version of WordPress 4.8.1 with no plug-ins and built-in theme for posterity, just the contents of the site. So we use wget to flatten our transform our sites to static HTML, CSS, and JavaScript (no database functionality). Ideally we also remove external dependencies as much as possible, though link rot—external links that go to no-longer-extant sites—will always be a problem.
An example of a flattened site is RRCHNM’s first podcast, Digital Campus TV. We used wget to generate a static version of the site, fixed up the HTML and put it online. (I give myself a shout-out for that one.) This is our preferred solution for sustainability, because it requires almost no upkeep to sustain these sites. In 10 or 50 or 100 years, browsers will still be able to read HTML or if there is such a major overhaul in the structures of the web that there is no backwards compatibility to HTML then there will be a straightforward upgrade path from HTML to UtopiaML that we take once for all our projects which will then be good for another century or two.
Our last type of sustainability is reinvention. The aforementioned World History Commons combines the content from eight previous RRCHNM websites in to a single “commons.” This is the kind of project that we get external funding for and so is the exception rather than the rule.
There are other ways to sustain sites, such as containerization and emulation, but I’m going to be really honest here: that takes time and money, and the containers and emulators themselves have to be sustained. Flat HTML, CSS, and JavaScript is about the easiest thing to keep going on the internet. Websites we created in the 1990s are in better shape than the ones we created in the early 2000s because they were HTML and didn’t involve PHP, databases, or content management systems. Even the dreaded Flash is easier to deal with than a severely out of date content management system. If you have one or two really complex digital objects you want to save… sure, go for emulation. I am always up for a trip down memory lane by starting up Dos-Box on the Internet Archive and playing the Oregon Trail, the game which led some people to call people my age “the Oregon Trail Generation.” But if you’re trying to save a longer digital backlist of a dozen or a hundred or hundreds of projects, it’s going to be time consuming. Y’all have been warned.
Instead, I think we’re better off following the example of the Endings Project team, and focusing on creating add-ons to make flattened sites more functional for people used to dynamically generated content, for example a search function that can be deployed on static websites, so there’s no need for an underlying database to search the site.
Preservation in Practice
Okay, I want to turn now to preservation, which I’ve argued is separate from sustainability. This is for when you have a cool, custom coded website from the 00s that no one visits anymore or a course websites from the 1990s might be of interest to future historians of education and don’t want to get rid of it, but it also doesn’t need to be sitting on our servers. At RRCHNM, we preserve digital projects by sending them to Mars.
(I just can’t resist making that joke all the time.) We send them to MARS: Mason Archival Repository Service, or GMU Libraries’ D-Space Repository.
Here’s where I give a shout-out to the amazing Andrew Kierig and now Joanna Lee, who have worked with us to figure out a way for the libraries to support preservation of complex digital objects in a way that didn’t just off-source all our technical debt onto them, but rather fit into their existing technical infrastructure and actually used resources in a way that helped them justify having that infrastructure.
An aside: don’t try to foist your DH websites off onto librarians. Not unless you and they both agree that’s the path forward from even before you start the grant application and they get paid for their troubles from grant funds.
When we use wget to create static versions of the site, we also create a WARC—Web ARChive file. We then zip up the project website and upload it, the warc file, screenshots (in TIFF, because those aren’t lossy, but sometimes also in JPEG because annoyingly the repository can show image previews of JPEG and PNG but not TIFF files which have to be downloaded to be viewed), associated documentation, and of course metadata to the GMU institutional repository.
This, by the way, for any critical code scholars who’ve been pulling their hair out at my casual disregard for the original code bases of our projects. This is where we finally do save original code bases. Our system’s administrator God’s Will (and now Tony) performs code dumps for custom built sites, where part of the intellectual value of the site is what did to create them and those are also zipped up and uploaded to MARS.
You can see here a list of our project metadata, which lead to many of the questions we wrangled with while uploaded the metadata:
who is an author? PI? PM? coPI? advisors? content creators? coders? people who’ve maintained the site?
what is the title of the project? the site URL? something else?
what is the date of the project? when there’s a date range, we can use the last published date but what if we don’t know when the site was last touched?
what does it mean to publish a digital project? RRCHNM is the (self-)publisher
type and keywords need to be project specific
information on sponsors is crucial
abstract describing the project is what people see when the visit the project page in MARS
Note there’s a line here about items not deleted from servers… we preserve sites that we are no longer updating even as we continue to sustain them, because there may come a day when we no longer are going to sustain them. By preserving them as soon as we’re done updating them, we get them in as close as possible to original—and fully functional—condition
Speaking of which: if you only take one thing away from this blog today, whether you want to sustain or preserve your project, DECIDE WHAT TO DO AS SOON AS POSSIBLE, AND DO IT AS SOON AS POSSIBLE. Do it even before project starts, if you can, but any time before the end of active development can work.
After active development ends, and there’s no money to pay for people to work on the project, things get harder to fix. Once supporting files go missing and code breaks, it’s harder to fix. Once the PI leaves the uni and you don’t know who to talk to about what the site is supposed to do and look like, it’s harder to fix. Once the entire project team has left the uni and you don’t know what promises were made to funders or outside organizations, it’s harder to fix.
If you need help with these conversations and decisions, Alison Langmead and the folks at Pitt have created an excellent series of resources to help you work your way through this: the Socio-Technical Sustainability Roadmap.
If you go into MARS, you’ll be able to see what a “preserved” digital project looks like for us. It’s basically some metadata and a bunch of file downloads, but anyone can download those files and see what the website looked like or spin up a local copy of the flattened site on their computer to explore or in some cases dig into the original code base to see how it was made. This is obviously a world away from a sustained project, but it’s not just deleted off the servers without making a publicly-accessible backup somewhere else first.
This isn’t to say we don’t just delete things sometimes—there are some pieces of a project, prototypes, ideas that don’t go anywhere, dev sites for projects no longer under development, and so forth—that don’t need to be sustained or preserved. Ephemerality can also be a deliberate choice and sometimes a valuable one, as anyone who’s chosen not to record a classroom Zoom discussion knows full well.
Conclusions
To get back to the big picture and if I may be forgiven getting mathematical and drawing a Venn diagram…
You will have to decide own criteria for what goes into which circle. Our criteria are very much tailored for historians building websites for the purpose of democratizing history and making historical sources, methods, and arguments available beyond the ivory tower. Someone making digital art may feel very differently.
But whatever your criteria are, you need to borrow at least a little of the mindset of car owners or—to go back to the tried and true metaphor—of publishers and librarians who have scarce resources with which to publish or preserve a piece of scholarship.
We, as DHers, have scarce resources with which to sustain and preserve our digital scholarship. Most of us are doing it ourselves and don’t have unlimited time or money, especially with the “publish or perish” mentality of academia where you can’t just do one project and say that’s it, you’re good for the rest of your career. We accrue projects and then we need to make decisions about how to managed our backlist of previous projects.
Some suggested questions to help guide you:
what are you saving?
BE THOUGHTFUL ABOUT THE PIECES OF YOUR PROJECT
why are you saving it? who is going to want it?
BE REALISTIC ABOUT YOUR AUDIENCE!
how are you saving it?
ONCE YOU KNOW YOUR AUDIENCE, YOU KNOW HOW THEY NEED TO ACCESS IT
what resources do you have and what do you need to prioritize?
WE ALL LIVE IN THE REAL WORLD
how much can you “future-proof”?
THE LESS WORK YOU HAVE TO DO IN THE FUTURE, THE MORE YOU CAN SAVE
I want to end once again by saying thanks to everyone at (or formerly at) RRCHNM who has helped on this gargantuan project! It’s easy to see me writing about this work and think I’ve done it all myself, when it wouldn’t have been possible without the rest of the RRCHNM sustainability team.
When a university press contacted me to peer review a book for the first time, I was thrilled. I was recognized by someone as an expert! And being paid for that expertise didn’t hurt either.
Then I was anxious. Did I actually *know* how to write a peer review? I’d published a few articles and book chapters, but the peer reviews I received on them varied WIDELY. On one article, the reviews ranged in length from 480 words 1,726 words. On one chapter, I was told no revisions were needed except for some minor typo fixes that the editor took care of for me. Some reviewers have been off-base enough that editors have told me to mostly ignore their feedback and other reviewers have been so spot on I’ve wanted to weep with gratitude. (Let me take a moment to thank EVERYONE who has left me such thoughtful reviews – you are amazing and I appreciate your feedback so very much.)
Surely presses expected a lot from someone they were paying to review an entire book, but I’d not yet received a monograph-length peer review and had no sense of how they compare to article/chapter peer reviews. What were they expecting? How much did I did to write, and what about? And how much time, in an already very busy semester, would this take from my own research and writing?
The good news is that editors know what they want and are happy to give guidance on that. It’s pretty standard for editors to give you a set of guiding questions to keep in mind while you’re reading and I’ve used those to shape my reviews. You can ask to see those guidelines before agreeing to review a book (they’re not confidential, as far as I can tell) but I’ve also collated a few of the common questions that seem to be asked into four main categories.
Go/No Go? The press will usually ask if you recommend publishing the work and if it makes an important/valuable contribution to scholarship. To my mind, this is the most important feedback I can give them, so I like to start my review with a 1-2 sentences answering these questions.
Argument? The press will also ask you to summarize the argument/thesis and themes of the book. You might be asked whether you think the author actually accomplishes what they set out to argue, or if the author has missed some topic or point of view that is necessary to make the argument. In other words, what do you think is the point of this book?
Organization? The press wants to know if the book makes organizational sense. Are there any long digressions that can be cut? Are there areas that can be expanded? Does the length of the book make sense (should it be longer or shorter) and are all the ($$$) illustrations necessary? This is where you get down to some of the nuts and bolts of how the author proves and supports their argument.
Audience? At the end of the day the press is in the business of selling books, so they want to know who will buy this book. Will it be used in courses (if so which ones) or will this appeal to a general audience? What are the venues where this book should be promoted? Are there other books that this could be promoted alongside or that are in competition with this book? In short, even if this is the best book ever written, someone needs to be willing to buy it.
Those are the main four points I attempt to cover in my main analysis, but when appropriate I also try to include chapter notes (e.g. for a full manuscript review rather than a proposal review). Basically, when I read through the manuscript, I take detailed notes on a chapter by chapter basis which I tidy up at the end and tack on to the end of the main analysis. The “big idea” feedback is very helpful for the editors, but the “hey, you should fix this paragraph, its description of xyz concept is unclear” will be helpful for the revising author when they’re hacking through the weeds.
In closing, I want to turn back to numbers to give some thoughts on how much to write and how long a review takes. Right now I have two data points, but I’ll add more as they occur.
Review 1, full manuscript: this took about 4 days to read, review, and write up my notes. The main analysis was 823 words and the chapter-by-chapter notes were an additional 2741 words. For this, I was offered $200 in cash or books, which works out to 5.6¢ per word or $6.25/hour.
Review 2, proposal + sample chapters: this took somewhere between 2-3 days to read, review, and write up my notes (this happened in the middle of chaos of the COVID-19 pandemic so that time was broken up over multiple weeks and I had to do a lot of re-reading, it should have been faster). The main analysis was 1,166 words and I didn’t include chapter-by-chapter notes. For this, I was offered $100 in cash (or $200 in books), which works out to 8.5¢ per word or $4.16-$6.25/hour.
Review 3: TBA!
I would say the key takeaways of this are:
At least for me, peer reviews always take longer than I expect them to because I’m usually taking far more detailed notes than if I’m reading a book for course prep or my research.
They will go faster if I can find a dedicated chunk of time to work on the review, so the details don’t leak out of my mind, and that’s a factor I’ll keep in mind now when saying “yes” or “no” to a request.
And I’m not going to get rich doing peer reviews! But the money’s not bad, either, and as a bonus I get to read some really cool books. Because, let’s face it. I’m an historian. Most of us are book addicts. When someone asks if I *really need* all those books in my office, the answer is an unqualified yes. And actually, I could use a few more…
NOTE: This is a lightly edited version of a talk I gave at the inaugural Chesapeake DH 2020 conference. My original intention was to wait to publish this until after June, to see if the trends I’d identified continued through this year’s DHSI. But the disruptions of the COVID-19 pandemic and the subsequent cancellation of pretty much everything have created enough of a rupture in the dataset that I’ve decided it is not advisable to extend my analysis past 2019.
TL;DR – people have wondered if DHSI Twitter is dying. I hypothesize, based on my analysis, that it is not dying so much as democratizing. First, we saw an explosion of Tweets as the network expanded to encompass more than a clique of early adopters (2014-6), then we saw a contraction as many Twitterati moved on or moved into the instructor corps (2017-9), leaving more “space” in the network for everyone else.
Rise and Fall of the DHSI Twitterati? A Longitudinal Analysis of the Digital Humanities Summer Institute Twitter Hashtags from 2012-2019
Digital humanists have been using Twitter to share their experiences at the annual Digital Humanities Summer Institute since at least 2009 and Twitter has become a staple of the DHSI experience, with official hashtags, organizer accounts, and a variety of prizes awarded to prolific or entertaining tweeters. But beginning in 2018 and again in 2019, people noted the decreasing volume of DHSI tweets, with one user speculating this might be “finally the turn away from twitter“. While it’s a bit soon to toll the death knell of DHSI Twitter—800 people wrote over 5000 tweets on the #dhsi19 hashtag—the absolute numbers do seem to tell a simple tale of an increasing number of people tweeting in the early part of the decade, which peaked in 2015 and 2016 and has been in decline ever since. However, these absolute numbers are a mask for series of more complicated patterns. This talk looks at DHSI Twitter from 2012 through 2019, examining the changing institutional circumstances of the institute, the expansion and fragmentation of the initial tweeting clique, and the role of power-tweeters (or “Twitterati”) in developing and sustaining DHSI Twitter.
I’m going to skip any detailed discussion of method and instead point you to my Twitter Methods Ur-Post if you’d like to read about data collection and processing. While I collected most of this data myself, I’d also like to give a shoutout to Jon Martin for collecting and sharing the first years in this dataset.
While I’ve collected Tweets over varying lengths of time, you can see from this graph the number of total DHSI tweets in 2017 that there is a sharp increase in number of tweets before the event and an equally sharp decline after the event, which made me comfortable cutting off long tail of tweets before and after DHSI without fear of missing too much.
This is a visualization of +/- 2 days for 2017 so can see boundaries more clearly. In general, there is a pattern of a sharp uptick in the number of tweets in the first three days of each week – as people are traveling, then excited to be at DHSI – followed by a decrease over the next two days – as people are getting stuff done – with a bit of an uptick on the last day – as people give one last hurrah and declare the week was fun. There’s a sharp decrease over the weekend between the two weeks of DHSI, and an equally steep drop off at end of the entire event. Because of this, I feel comfortable focusing on the primary dates of each year’s DHSI, plus or minus 1 travel day (e.g. for 2017 this would be days 155 to 168 in the visualization above).
With those preliminaries out of the way, on to the fun stuff! If you look at the total number of people Tweeting at DHSI, concerns about decrease in Twitter activity seem correct if perhaps a little overblown. There’s a steady decline in 2017, 2018, with sharp drop off in 2019, less than any year since 2014, but who knows what 2020 would have looked like under other circumstances.
If we look at total number of Tweets, we get the same tale but perhaps more starkly. There is a peak in 2015, fewer Tweets in 2016, a slight recovery in 2017, and a sharp drop off in 2018 and 2019 which take us back down to the level of 2012. The sharp drop in 2018 all the more remarkable for the fact that total number of Tweeters was relatively steady from 2017 to 2018 – there were 20 fewer people but almost 5000 fewer Tweets!
But if we look at second bar in this chart – which is Tweets per week – we see the first complication in this simple narrative. In this column, the sharpest drop-off was actually between 2014 – the last year DHSI was 1 week only – and 2015 – when DHSI attempted to expand to 3 weeks in a grueling marathon. While this might logically have been expected to produce a threefold increase in Tweets, attendees report severe burnout and the institute was scaled back down to 2 weeks for all subsequent years. Indeed, burnout remains an issue and attendees are warned against it annually.
The total tweets per week recovered a bit in 2016 and 2017, but never reached heights of 2014. By that standard, DHSI Twitter has been dying since 2014.
The second complication emerges when we look at a subset of the DHSI Tweeters, who I like to call Power-Tweeters or the Twitterati: people who Tweeted more than 100 times during any year of DHSI. To reach the status of Twitterati, a person has to produce 20+ Tweets a day if they only attend 5 days, or 9+ Tweets a day if they attend 2 weeks as well as the weekend in between. I’ve mapped here all the Twitterati, as well as subdivided the group into people with 200+ Tweets and people with 100-199 Tweets. (Note that, while 200 is the minimum number of Tweets to be in the first group, some people in that group are Tweeting 400, 600, even 817 times in a single DHSI.)
There aren’t many people who made it to 200 tweets when DHSI was only 1 week and we see the number of Twitterati in this category double in 2015, when the event went to 3 weeks followed by a decline in 2016 when the event was scaled back to 2 weeks. The number of Twitterati in the 100-199 saw its biggest increase a bit earlier, in 2014, and its biggest decrease also in 2016. But the number of Twitterati in this group have actually been holding steady since 2017, with even a slight increase into 2019.
This is in sharp contrast to the 200+ Twitterati. There was a spike in their numbers during 2017 followed by a huge drop off to 2018. In 2017, the twelve 200+ Twitterati were responsible for 3741 Tweets, but in 2018 the three 200+ Twitterati barely managed 781. In other words, 3000 of the 5000 Tweet difference between 2017 and 2018 can be accounted for by the decreased activity of this group. The trend continued into 2019, when only one person who managed to make it over 200 Tweets, and they barely squeaked over that line at 216.
So when it comes to the forces driving the overall number of DHSI Tweets, it seems clear that what we’re seeing is a drop in the number of Twitterati. While there’s also been a drop in the overall number of Tweeters, that seems more closely correlated to the drop in attendance at DHSI from 2018 to 2019.
For those who are interested in the numbers, here’s the chart where you can can see how Twitterati correlate to number of Tweets and the sharp drop off in both for 2018 and 2019. It also shows the changing overall attendance numbers for DHSI. (Note that this column counts people twice if attended both weeks and uses public registration lists to determine attendance so it is not 100% accurate but close enough for our purposes.)
In this chart, you can also see a third possible complication that might be driving some of these numbers, which is the weekend conference. While the ADHO Sig Pedagogy and DLF events were great, those were also offshoots of a scholarly conference that happens at other times of year (the international DH conference and the DLF Forum, respectively). By contrast, 2017 was the year that SHARP held its one and only conference in conjunction with DHSI. And SHARP is another event that has historically been filled with Tweeters, with Twitter prizes and attendees who were paid to live-Tweet the conference in multiple languages. So a lot of what is driving the anomalous numbers in 2017 can actually be pinned on SHARP and SHARP’s Twitterati.
At this point, we’ve seen a few complications to our original, simple narrative, and hopefully I’ve intrigued you about the role of Twitterati at DHSI. Now it’s time to move onto… the super-network! Here is a visualization of the entire DHSI Twitter network from 2012-2019. It has 6539 nodes and 69594 edges (the red edges are 2012, orange is 2013, through to purple which are 2019 edges) in 43 connected components, of which 98.1% of nodes and 99.84% of edges are in the giant connected component.
And because network visualizations like this are always spaghetti monsters, here’s a slightly closer view, with nodes sized by degree – the number of times the person with that Twitter handle Tweeted or was Tweeted to/about – and colored by modularity class – algorithmically generated subnetworks. From here, you can already begin to see some of the Twitterati’s handles pop out, such as dorothyk98, profwernimont, DHInstitute, and AlyssaA_DHSI. I’m hanging out in the upper left hand corner. But this visualization also begins to let you see the sheer number of people who’ve attended and tweeted at DHSI over the years and how little the network has shifted over time. That is, there are no clear subnetworks, where each year emerges as an independent cluster of nodes.
You can see that a bit easier here, with each year separated out in the visualization. If you look closely, you can see there has been some drift over time:
the red 2012 nodes are mostly to the bottom left of the combined visualization
the pink 2013 nodes are to bottom right with some 2012 overlap
the orange 2014 nodes are in the center and low bottom with significant 2013 overlap
the yellow 2015 nodes are in the center with significant 2014 overlap
the green 2016 nodes overlap most of 2015 and are a bit higher in the visualization
the teal 2017 nodes overlap 2015 and 2016, but are a bit off to the left/top
the dark blue 2018 nodes overlap 2017, but are a bit off to the right/top
the purple 2019 nodes overlap most of 2015-8 and are a bit lower in the center
This is consistent with many people coming to DHSI for several years (mostly in a row) then stopping when no longer need training. Alternatively, they move into the instructor pool and stop Tweeting as much or stop Tweeting altogether because they’re too busy instructing.
Separating them out also lets you see the year Twitter really “caught on” was between 2013 and 2014 – the numbers of Tweeters and connections doubled, while the density of network halved. That is, this was no longer a tight clique of a few Tweeters but lots of people sharing the hashtag space.
These are statistics on the network for each year’s DHSI. I know force-directed graphs are prettier than charts, but this chart lets us start to get into the meat of the network analysis, for example by showing you the changes I was just talking about between 2013 and 2014 more clearly. Far from 2014 being the year DHSI Twitter started to die, from a network analysis standpoint 2014 is the year DHSI Twitter finally caught on.
Moving forward in time to examine the two years where DHSI’s format changed dramatically – going from 1 to 3 to 2 weeks – we see the slow evolution of the Twitter network and how it only partially reflected those changes. There was a slight increase in Tweets/connections from 2014 to 2015, but it wasn’t proportional given the move from 1 to 3 weeks. We also see the graph density continue to decline, which makes sense: people attending only week 1 might not Tweet to those in week 2 or 3. The number of Tweeters increased from 2015 to 2016, and the number of overall connections decreased but again, it wasn’t proportional given the move from 3 to 2 weeks.
2017 stands out as an anomalous year in the network analysis as well. The number of Tweeters and connections decreased slightly from 2016 to 2017 but the number of connected components tripled. The average degree and density also increase a little, suggesting that SHARP attendees’ participation in the DHSI Twitter network both (slightly) increased the connectivity of its main connected component while at the same time fragmenting parts of it into far more numerous unconnected components.
In 2018, the number of Tweeters and connections both decreased markedly – as people were noticing on Twitter – but the number of Tweets actually declined at a much faster rate than number of connections. Again, this gives support to the hypothesis that these changers were driven by the Twitterati decreasing in numbers. People were still using Twitter to connect to each other, even if they weren’t producing as many tweets. Similarly, the number of Tweeters decreased markedly from 2018 to 2019 but the number of overall connections didn’t decrease in proportion to the decrease in the number of Tweets.
In other words, the DHSI Twitter network was still functioning as a network even though it seemed to have gone (relatively) radio silent.
To consider the importance of the Twitterati another way, I first visualized the network without them. For the purposes of the DHSI “super network,” I defined the Twitterati more generously as anyone who has tweeted over 200 times at all DHSIs combined (so anyone who’s been at 3 or more DHSIs might get into the Twitterati even if weren’t in the Twitterati for any 1 year). This cuts out a mere 2% of the nodes but a whopping 75% of the edges.
Another way to think of this is to note that 36% of the DHSI Twitter network consists of nodes that are connected to it by 1 Tweet and another 17% are connected by 2 Tweets. In other words, the VAST majority of people connected to DHSI hashtags are the weakest of possible ties – 1 and done. But these nodes share a quarter of the edges in the graph with each other and almost half the edges with the Twitterati.
By contrast, the Twitterati themselves consist of 123 nodes. That’s it. Only 2% of all nodes in the network have tweeted 200 or more times over this 8-year period, and amongst themselves they generate a bit under a third of all the edges.
So where does this leave us as I cram in the last few words before I’m out of time? There is a very, very small number of people responsible for the vast majority of DHSI tweets, and if we zoom in to the 1000+ Tweets club, we can see how truly small a handful of people this is. There are 18 of them (well, us). Thus just a few Twitterati attending or not attending in a year (or, if you know who many of these pepole are, just a few Twitterati moving into the instructor corp!) can have an outsized impact on the network.
BUT ALSO, if you will allow me to return to an earlier visualization…
…it’s possible what we have been seeing in 2018 and 2019 is not the demise of DHSI Twitter so much as the democratization of DHSI Twitter. Each year, there have been fewer and fewer Twitterati dominating the conversations, making space for everyone else. And that is as beautiful a network as the super-network I started with. Thank you.
This is a stub blog post related to my presentations at the AHA 2020 Getting Started in DH workshop. It lists (and links) all the tools I expect to reference:
For some years now, I’ve been analyzing conference Twitter data and sporadically posting about it online, including twitter threadswrittenfromvariousairports. While I’ve had a method from the beginning, that method has evolved over time: most significantly, I got tired of endless hours of Open Refine data cleaning and automated the network creation process. (To be clear: I love Open Refine. But when you have a tedious, repetitive task, programming is your friend.) While it’s possible that my methods will continue to evolve over time – as technology changes and new research questions occur to me – this is the current state of my methodology and will be linked as the ur-post whenever I blog about Twitter analysis.
Data Collection
I collect my data from Twitter using Hawksey’s TAGS 6.0, which employ Google Sheets. Yes, I know there’s now a TAGS 6.1 but I subscribe to the philosophy of “if it ain’t broke, don’t fix it.”
The primary advantage of TAGS, for me, is the ability to “set and forget.” TAGS utilizes the Google Search API (as opposed to the Google Streaming API) in its limited, free version, which means that it can only capture twitter data from the last 7 days. To get around this limitation, TAGS can be set up to query the API every hour and capture whatever new tweets occurred since the tweet “archive sheet” has last been updated. This means it can be set up whenever I remember to set it up – usually weeks if not months before a conference – and it will continue running until I remember to tell it to stop – again, usually weeks if not months after a conference ends.
I try to download this data regularly to my computer, according to the data management principle LOCKSS: Lots of Copies Keeps Stuff Safe. Only having the data available in Google Sheets makes me dependent on Google to get to my data. By contrast, CSV files on my computer, which is Time Machined in two locations, have a decent chance of surviving anything short of nuclear/zombie apocalypse.
Data Cleaning/Pre-Processing
While the data that I get from TAGS is relatively clean, I do tidy it up a bit first. Most importantly, I deduplicate my dataset. Some of this duplication is my fault, when I’m trying to track hashtag variants and someone includes both variants in a single tweet (e.g. “aha2019” and “aha19”). TAGS also seems to duplicate some of its collection data, though I haven’t figured out why – manual inspection of each tweet’s unique ID makes clear when a tweet is an actual duplicate in the set vs. a delete-and-rewrite or a retweet of someone else’s tweet. Because deduplication is a simple process of checking whether each tweet’s unique ID occurs only once in the dataset, I’ve automated that process.
Depending on the analysis I want to conduct, I also tend to time-limit my dataset. Specifically, I delete any tweets (from a copy of the spreadsheet – no one panic!) that occur more than one “day” before the start of the event or one “day” after the end of the event. In this case, a “day” is defined as the GMT day, which may or may not correspond to the local timezone of the event. While this has the potential to cause slight discrepancies when comparing events across timezones – specifically, some events will have a few more hours of data capture before the event starts while some will have a few more hours after it starts – I don’t believe these changes to be statistically significant. If I ever do some hard math on the question, I’ll update this post to indicate the results.
Network Creation
Now to the fun stuff! I started analyzing conference tweets because I was interested in how people connect and share knowledge/ideas/opinions in this virtual space. As such, my primary interest lies in creating a social network from the twitter data – who tweeted at/mentioned who – which necessitates transforming the TAGS archival spreadsheet of tweets into a network of Twitter handles (and/or hashtags). Because Twitter handles are unique IDs, I only needed an edge list of sources and targets for each tweet (other data capture was and remains interesting-but-optional).
I originally did this manually. Aside from being tedious, this also created problems for replicability. That is, what if I slipped up and missed or repeated something while creating my edge lists? I therefore wrote a Python script to do this work for me, with a few variants for if I wanted to keep the hashtag, date/time information, or for my students using TAGS 6.1.
Next I imported the edge list into Gephi (though I’ve experimented with other software, Gephi’s old hat to me at this point and does what I need it to do) and allow it to sum repeated edges to give each edge a weight. That is, if I tweeted to or re-tweeted @epistolarybrown 173 times over the course of a conference, the edge from me to her would have weight 173.
Network Analysis
At this point in the process, I use Gephi’s built-in algorithms to conduct my network analysis, usually with an emphasis on metrics like degree, betweenness centrality, network diameter/path lengths, and modularity classes. For an example of how that works out in practice, check out one of my conference blog posts! And if you have any questions, feel free to ping me via Twitter.
This is an edited version of a lightning talk I gave at the Shakespeare Association of America Folger Digital Tools (Pre-Conference) Workshop.
In March of 2019, Meaghan Brown of the Folger Shakespeare Library came to George Mason University’s campus to run an encode-a-thon with the upper-level undergraduates who were students in my Early Modern England course.
For this event, we were working on the Elizabethan Court Day By Day dataset, compiled by Marion E. Colthorpe. While the origin of this project was an attempt to track Queen Elizabeth’s royal progresses through the countryside over the course of her reign, it morphed into a dataset tracking the events of her court for ever day of her 44-year reign. It includes not just a list of events but also select quotations from a wide variety of primary sources.
This dataset was donated to the Folger Shakespeare Library as a massive PDF. At over 2000 pages long, it’s a treasure trove of information about the peregrinations and events of Elizabeth’s reign. The Digital Media and Publications team at the Folger have extracted the information from the dataset into plain text and have been working to encode it, to facilitate future analyses of the data.
The first line of each day is metadata (colored red in the image to the right) where participants record the day, the type of event that has been captured, and the location of the event (where known). This particular month is February, 1601, chosen as the dates for the Earl of Essex’s rebellion – there are two events on the 7th and one on the 8th. While I wasn’t certain where Essex was when he refused to obey the Privy Council’s summons (politics), his followers were definitely at the Globe Theatre later that day, when the Lord Chamberlain’s Men performed Richard II (performance), presumably to get them in the right headspace for their attempted rebellion! The events of the 8th were somewhere in London, per the text, but at multiple locations within the city, hence the location is recorded at a larger scale than the single building of the Globe.
After adding (or editing some of the automatically generated) metadata about each day, students then marked up each day’s text by highlighting important words/phrases and clicking the buttons at the top of the interface to designate them as people (individual people, groups of people, or countries acting as people such as “Spain invaded”), places, dates, quotes, books, or general sources. While straightforward enough for a novice human encoder, this isn’t a task that can be done automatically for a lot reasons. For example, Essex is a person, a county, and also (in conjunction with the word “House”) a building in London.
Most of my students worked solely in the interface, but a significant minority also flipped over into the XML markup view and dealt with manual tags, especially when they were dealing with days that needed to be split into multiple events or other complicated encodings. As someone who is personally familiar with XML, this view was in a lot of ways easier for me to work with as I could see very clearly when I’d accidentally gotten a tag in the wrong space or included a space in a place tag, or other “messiness” that I know will have to be processed out in the final analysis of the dataset.
While my students weren’t entirely certain, going into the event, how exactly this “encode-a-thon” thing was going to relate to their other classroom experiences, when I briefed my students after the event, they identified a number of positive outcomes they’d had from the activity:
up-close and personal look at daily life among Elizabethan elite and their servants
humanized historical actors
looking at “raw data” of facts/events that forms historical narratives
variety of sources used to reconstruct narrative of events
coverage of major events that didn’t make it into the classroom narrative due to in-class time limits
work behind building historical datasets
critically think about categorization of events/activities
introduction to XML (advanced students only)
And, perhaps most importantly, in between them regaling me with the stories they’d uncovered – and linking those stories back to important points I’d made in class lectures and their assignments – they reported having fun.
For those of you who are unfamiliar with CRDH, it’s an annual, open-access and peer-reviewed publication with an associated conference – more information can be found on its website including past volumes of the publication, past conference programs, and (eventually) the new CFP for CRDH 2020. You should definitely come to CRDH 2020. And bring a friend!
As an inveterate conference tweeter, I spent a lot of time on Tweetdeck during the conference and was generally pleased by the amount of Twitter engagement we had given the small conference size. So in honor of the conference Twitterati (is that a word? It is now!) I’ve done a quick analysis and visualization of our activity.
Global Network Stats:
Nodes: 198 (people with separate Twitter @-handles)
Edges: 552 (tweets and retweets)
Average weighted node degree: 4.369 (@-handles were mentioned in an average of 4.369 tweets/retweets, including repeat mentions)
The network is disconnected (there are people who used the hashtag who never tweeted to each other or retweeted each other’s tweets) into two components and the largest connected component has diameter 5.
The Major Nodes:
When looking at the conference network, some nodes immediately jump out due to the node color/size scheme I’ve applied to the visualization: nodes with lower degree (less tweets originated with or included that @-handle) are blue while nodes with higher degree (more tweets originated with or included that @-handle) are yellow, orange, or red and progressively larger as we get towards the red/highest (unweighted) degree nodes.
If we look strictly at the numbers, the top nodes by (weighted) degree are jotis13 (yes, I’m writing about myself in the third person); jimccasey1; nolauren; JenServenti; CCP_org; profgabrielle; dgburgher; chnm; historying; seth_denbo; FreeBlack TX; and harmonybench. This is not, strictly speaking, surprising as these were heavy conference tweeters and/or presenters who included on their Twitter handles on slides for easy tweeting of their research.
However, if we look at betweenness centrality (which is another network analysis metric that measures, if you’re trying to get from one part of the network to another as efficiently as possible using the edges, which nodes do you go through?) we get both some familiar orange/red nodes as well as some of the yellow, middling-degree nodes: jotis13; JenServenti; jimccasey1; nolauren; seth_denbo; historying; CCP_org; profgabrielle; Zoe_LeBlanc; kramermj; and harmonybench.
The contrast between these two measures enables us to draw some conclusions about how different Twitter handles were functioning in the network. For example, both JenServenti and seth_denbo rank significantly higher in betweenness centrality than node degree; their importance as connectors in the network were higher than expected given their volume of tweets/mentions. Given their respective positions at the NEH and AHA, the fact that they’re also essential connectors in this Twitter network should perhaps not be surprising.
By contrast, CCP_org and profgabrielle rank higher in node degree than betweenness centrality. A quick sneak peek at a different network measure – closeness centrality, basically how central a node is to a network – shows that they are tied for the second highest closeness centrality in the network (after jotis13). So while CCP_org and profgabrielle may not be on as many of the shortest path through the networks (likely because those paths are routing through jotis13 instead) they are two of the three most central nodes in the network. In other words, their voices were vital to the conversations we were having (both in person and online).
Another particularly interesting thing to note about nodes with high betweenness centrality is that neither Zoe_LeBlanc nor kramermj were physically present at #crdh2019. While this is not an unfamiliar phenomenon – conference tweeting, by its very nature, enables the virtual inclusion of people at conferences – what is particularly fascinating is that both of them played a very similar role in the network. Specifically, they signal-boosted a conversation about the diversity of digital scholarship to a wide variety of people who were not present at #crdh2019 and didn’t necessarily participate in wider conference conversations.
The Viral(ish) Subtopic:
While there were several stand-out tweets that got more traction than others (including the first one pictured at the top of the image, citing Jessica Marie Johnson’s essay, Markup Bodies) one in particular got the most attention and spawned follow-up comment threads (both “on” and “off” hashtag). It was the record of the following brief conversation:
profgabrielle asked jimccasey1, “How many years did it take you to create your dataset?”
jimccasey1 replied, “Going on seven.”
The conversation then continued on (in real life and online) by discussing the fact that creating datasets are not often considered scholarship, despite the interpretation, analysis, and scholarly skill that goes into creating them.
A few scholars chimed in to note that their institutional Promotion and Tenure guidelines had been updated to explicitly include digital scholarship as scholarship, not service. But the conversation largely revolved around the difficulties digital historians face in producing work that doesn’t fit easily into the “monographs, articles, book chapters” model of scholarship that still dominates the majority of the field.
Others noticed that the issues digital historians face in getting their databases recognized a scholarship echoed issues public historians have already been struggling with, particularly getting recognized for the work they do in creating oral history collections. The related issue of crediting the incredible scholarly work of librarians and archivists – which forms the foundation for much historical scholarship – also came up (echoing a few earlier conversations wishing there were more librarians in the room with us!)
Thematically, these conversations tied in strongly with the historical conversations we were having about the need to recover and recognize the vital work of women – especially Black women – in our historical narratives. I want to particularly highlight the Colored Convention Project (CCP_org)’s Teaching Partner Memo of Understanding:
I will assign a connected Black woman such as a wife, daughter, sister, fellow church member, etc., along with every male convention delegate. This is our shared commitment to recovering a convention movement that includes women’s activism and presence—even though it’s largely written out of the minutes themselves.
Building a dataset is hard work, and it’s tempting to focus on the most easily recovered historical figures from the archives. The CCP commits to doing the extra research to figuring out, for example, that “a lady” is actually Sydna E.R. Francis. This is an act of scholarship and we need to figure out better ways to recognizing it as such.
Final Thoughts:
CRDH is a small conference, and a new one, but that enables us to see exactly how widespread its (Twitter) impact is beyond immediate participants in the conference. I haven’t done enough small conference analyses to draw any conclusions about whether or not CRDH is “punching above its weight,” but it’s clear that the conversations we had on Saturday – particularly the ones about recognition and credit, both historically and in terms of our own scholarship – struck a chord with people online and traveled far beyond those rooms in GMU’s Founders Hall. And for anyone who’s now wishing they’d been there in person, hopefully the #crdh2019 tweets will hold you over until the next issue of Current Research in Digital History is published this fall!
Notes on Method/Dataset:
This data was collected via Martin Hawksey’s TAGS. Because the hashtag was created during the conference and the Twitter conversation ended by Monday (yesterday), this is a complete dataset of all tweets with the conference hashtag to date. I’ll be tweeting this blog post with the hashtag, so it will not be a complete dataset of all tweets with the hashtag because that would get circular fast…
For full information on my network creation methods, see this blog post.
It’s that time of year again: job adverts begin popping up online, academics polish up their CVs, and all the grad students, contingently employed scholars, and other job-seekers begin praying that they’ll be employed this time next year. I’ve been incredibly fortunate to have been employed by Carnegie Mellon University Libraries for the past four years, first as a CLIR-DLF Postdoctoral Fellow in Early Modern Data Curation on the Six Degrees of Francis Baconand then as the Digital Humanities Specialist.
When I accepted that postdoc, I had no idea what kind of career path I was getting into, I only knew I wanted Six Degrees to exist! But thanks to two years of careful time-logging and an hour or so of data cleaning and visualization, I can now say a little bit about what a DH job in a university library looks like. With the caveat that every institution (and even similar positions within the same institution!) is different, here’s what it looked like for me at CMU.
The Global Stats
I kept consistent track of my hours from January 22, 2017 through August 11, 2018 for a grand total of 81 weeks. In those weeks, I worked a total of 3148.2 hours or an average of 38.87 hours/week. CMU considers “full time” to be 37.5 hours a week, which means I worked 104% of full-time. Given that academia promotes a culture of overwork, I’m quite proud at the work-life (or should I say, work-medicalDrama) balance I managed to achieve.
The Temporal Stats
CMU allowed me flexible work hours, which is to say that I didn’t need to be in the office 9am-5pm every M-F. This is a good thing, because I spent almost the entirety of the 81 weeks covered by this analysis in physical therapy. While I’m happy to talk more elsewhere about disabilities in academia, I’ll just mention here that my flexible working hours were the only thing that kept me from having to go on short-term disability at one point. So it was a win-win for us both.
As is indicated in this visualization, I did most of my work in the “compressed” work week of Mondays through Thursdays with around 600 hours on each day. On Fridays, I only managed to do about 2/3 the amount of work I did during those main work days, but I did another 1/3 of that amount each on Saturdays and Sundays. The lack of productivity on Fridays is disappointing (but unsurprising – I always felt burnt out on the week by Friday) because those were supposed to be my dedicated 20% personal research days. However the Saturday/Sunday rebound shows that I did get the work done, just at a slower weekend pace. Not all weekend work was research though; those hours also includes conference travel.
One of the most surprising things I found in my data was that, despite my assertions about not working 9am-5pm, I actually did manage to do most of my work during a normal working day of 8am-4pm. The earliest hours generally reflect conference travel (and if you check out the interactive version of these visualizations via Tableau Public you’ll see one that includes duration alongside start time which shows this) along with a smattering of email checking. While my regular working day sometimes started as early as 6:30 or 7am, my activity levels really spike in the 8-9am period. That slight downtick around 11am reflects my zealously guarded lunch break, while my afternoons had a lot of meetings that started on the hour rather than the quarter or half hours. My activity levels start to drop after the 3pm meetings, but you can still see quite a lot of late afternoon and evening hours that I worked, sometimes up until almost midnight.
The Categorical Stats
That’s nice, you might be thinking, but WHAT did I actually do during my working hours? While many library positions have defined “percent times” that are supposed to be spent on any particular activity, my dean took the position that faculty should have the freedom to determine their own priorities.
In practice, my time broke out into
15% – professional development, including conferences
13% – dSHARP digital scholarship center, including co-writing the proposal to found the center, outreach and networking, setting up the administrative infrastructure for the center to run, organizing and running events, and our weekly “office hours”
12% – communication (particularly email… so much email…)
11% – travel (both around Pittsburgh and to conferences)
7% – consultations, library meetings, book orders, and other library administrative tasks
6% – teaching (guest lectures, managing independent studies, and workshops)
5% – personal research
4% – “other,” which is my category for activities such as networking, organization, and documentation
3% – committees
If I were to collapse that down into more “global” categories, I would characterize this as:
39% – dSHARP, consultations, communication, committees, and other library administration/service
33% – research, digital projects, and professional development
11% – travel (both around Pittsburgh and to conferences)
6% – teaching (guest lectures, managing independent studies, and workshops)
(For the eagle-eyed mathematicians among you, the missing 11% were holidays and paid time off, aka vacation days, and yes I took real vacations.)
When I put it that way, it’s clear my job was awesome! But for folks who haven’t spent a lot of time working in a library or on digital projects, it may not be entirely clear what I actually mean when I talk about co-running dSHARP or collaborating on a digital project. For that, my sub-categories will be far more revealing of my day-to-day reality.
By far the majority of my time was spent in meetings, at 22%, followed by 15% of my time spent at conferences and networking/performing outreach. You can really see my communications preferences as well – I spent 11% of my time emailing people, making it the third highest sub-category, while phone communication barely squeaked onto the visualization. Guest lectures and consultations total 7%, while administration (aka filling out paperwork and creating/documenting center workflows) is only 6%. That last stat really surprised me because it felt like so much more of my job! Then again, that translates to 178.8 hours of paperwork, so it was a significant effort despite its low percentage.
Take-Aways
There are a number of different conclusions that could be drawn from this data, but the ones I would highlight are
This job enabled me to maintain a very good work-life balance.
While my flexible working hours were essential to being able to work continuously through my health problems, I did the majority of my work during a regular 8am-4pm workday. That said, I also did significant work on weekends and evenings.
I spent 1/3 of my time on research and professional development. Not all library jobs have a significant research component, but many of them do, especially in institutions where librarians have faculty status.
Most of my research time was dedicated to collaborative digital project work and I didn’t manage to carve out as much personal research time as I would have liked. That boils down to my personality, specifically prioritizing external collaborative deadlines over self-imposed personal deadlines.
Because of the intensively collaborative nature of my work, I spent a lot of time in meetings and emailing people. A lot of time.
At the end of the day, CMU Libraries was an awesome place to work and a great career move for me. It played to many of my strengths while giving me significant flexibility in terms of when and where I did my work. So for any PhD job-seekers who’ve made it this far and feel like this might be the kind of position for them, I’d highly encourage you to check out the CLIR-DLF Postdoctoral Fellowship Program, which seeks to provide PhDs with practice experience in libraries and an entry into library-based careers. And for the rest of you, I hope this peek into the world of librarians was interesting and gives the digital humanists among you some ideas for future collaborations with a librarian on a campus near you.
I have been privileged to work with several awesome graduate students this semester, including Cordelia “Cory” Brazile and Lauren Churilla. A few weeks ago, we had a thought-provoking conversation about using Wikipedia in the classroom that inspired this blog post.
I’m sure I’m not the only one who despairs when my students cut-paste out of Wikipedia in their classroom papers. But the ship of “don’t use Wikipedia” sailed at least a decade ago, if not more, and honestly it’s not completely different from the age-old problem of “don’t copy from encyclopedias.” Tertiary sources have always (for definitions of always involving everyone alive today) been a part of our academic landscape and have clear uses for both research and pedagogy so banning the use of encyclopedias (crowdsourced or not) makes no sense. We need to use them responsibly and teach our students to do the same.
Enter Wiki Edu, a set of online resources dedicated to supporting teachers who want to incorporate Wikipedia assignments into their syllabi. If you have the desire and inclination to structure a major classroom assignment (equivalent to a whole-semester or half-semester research paper) into your syllabus, I highly recommend checking the site out. It includes a host of video resources that teach students how to edit Wikipedia – including videos on copyright and attribution – and teachers who register their classes on the site can get technological and staff support during the assignment.
That said, not everyone has the time or inclination to engage that intensely with Wikipedia. Our syllabi are jam-packed with everything else we need to convey to students and many teachers don’t want to reinforce an encyclopedia-like “history is facts” mentality over the argumentative, thesis-driven model of historical writing. So what are some alternatives? This is the list Lauren, Cory, and I brainstormed.
Explore an article edit history to see how the “facts” emerge over time.
Using the example of the World history article, students can use the “view history” link to see the original version of this article in which a user snarkily defined world history as:
First the earth cooled.
Then the dinosaurs got too big and fat so they all died.
Referneces:
Johnny, “Airplane – the Movie”
(Among other things, this provides students with a window into why some teachers view the site with serious skepticism…) In the following years, the page was redirected to “History” more generally, then redirected again to “History of the World,” before finally becoming a brief definition of the field of World History and expanding from there. Guiding students through a journey likes this helps them understand the evolution of the “facts” that they often take for granted when reading a Wikipedia article.
Explore an article’s talk page to see how the “facts” of controversial subjects are negotiated among interested parties.
The Wiki Edu resources deliberately steer students away from editing controversial articles (which is smart given their assumptions that students are editing/writing articles) but exploring these controversies can give students a peek behind the curtain of Wikipedia’s vaunted “neutrality.” Each article has a talk page, where editors can discuss changes before making them (or debate changes if someone else has reverted their changes). Exploring an article’s talk page in addition to the edit history gives an added dimension to the goal of exposing students to how historical consensus emerges in the case of controversial subjects. As a bonus, the talk pages themselves have a edit history! Reading the edit history of, say, the Black Lives Matter Wikipedia talk page is a fascinating exercise in the construction of Wikipedia article, in addition to educating students about the emergence of the movement. Wikipedia maintains a page with a list of controversial articles, which range from politics to sports, as well as a page on Wikipedia controversies.
Examine the bibliographies of articles and assess the chosen sources for bias.
Despite Wikipedia’s attempts to create “neutral” articles, which don’t favor any particular point of view over another, it doesn’t always succeed. Sometimes the bias is overt and comes under review or is tagged as biased. In other cases, however, the bias emerges only by carefully reviewing the sources chose for citation. My favorite biased article (yes, I have a favorite) is the Long Parliament article, which is almost entirely derived from the work of two nineteenth century publications and is very Whiggish. I’ve been using it as an object lesson to my students for over four years now and eventually someone will fix it but it hasn’t happened yet! Exploring the bias in this particular article also leads to a greater discussion of the nature of copyright, what sources people seeking to edit Wikipedia have – or don’t have – access to, and how lack of access to cutting-edge academic research might create barriers to public understanding. Insert discussion of the Open Access movement here…
Find articles that have been flagged for lack of citation and see if students can find reliable citations for them.
Wikipedia flags articles that need additional verification as well as maintains a page with a list of all these articles. (It even includes a button “I can help! Give me a random citation to find!” to get people started.) Asking students to work on a particularly under-verified article requires them to discover research sources outside of Wikipedia. Students then can practice providing sources for assertions of fact or determine that alleged facts lack citation because there is no evidence for them and modify the articles accordingly.
For multilingual students, examine the difference between the English language version of a article and the version in a different language.
We know that Wikipedia exist across multiple languages, but not everyone realizes that articles can differ radically between languages. The English Wikipedia article for King Sancho IV of Castile, for example, is a mere 5 sections long, most of which are genealogical, while the Spanish version is over twice as long with 11 sections. Comparing the two helps introduce students to the idea that “facts” and “common knowledge” can actually be culturally – in this case linguistically – determined.
Last, but not least, conduct targeted article edits.
Just because you don’t want to spend a huge chunk of your semester doing a Wikipedia assignment doesn’t mean that it can’t be productive to do some group live-editing of an article during class, or as a single homework assignment. Showing students how to make simple tweaks to the site gives them a better understanding of the crowdsourced nature of the site and how it’s constantly being updated – and may reinforce both a sense of publicly contributing to knowledge instead of writing solely for an audience of the teacher, as well as the idea that perhaps they should question the veracity of things they read online, instead of taking it all for granted.
So those were our ideas! If you have any other great things you’ve tried out with Wikipedia in the classroom, I’d be interested to hear it.



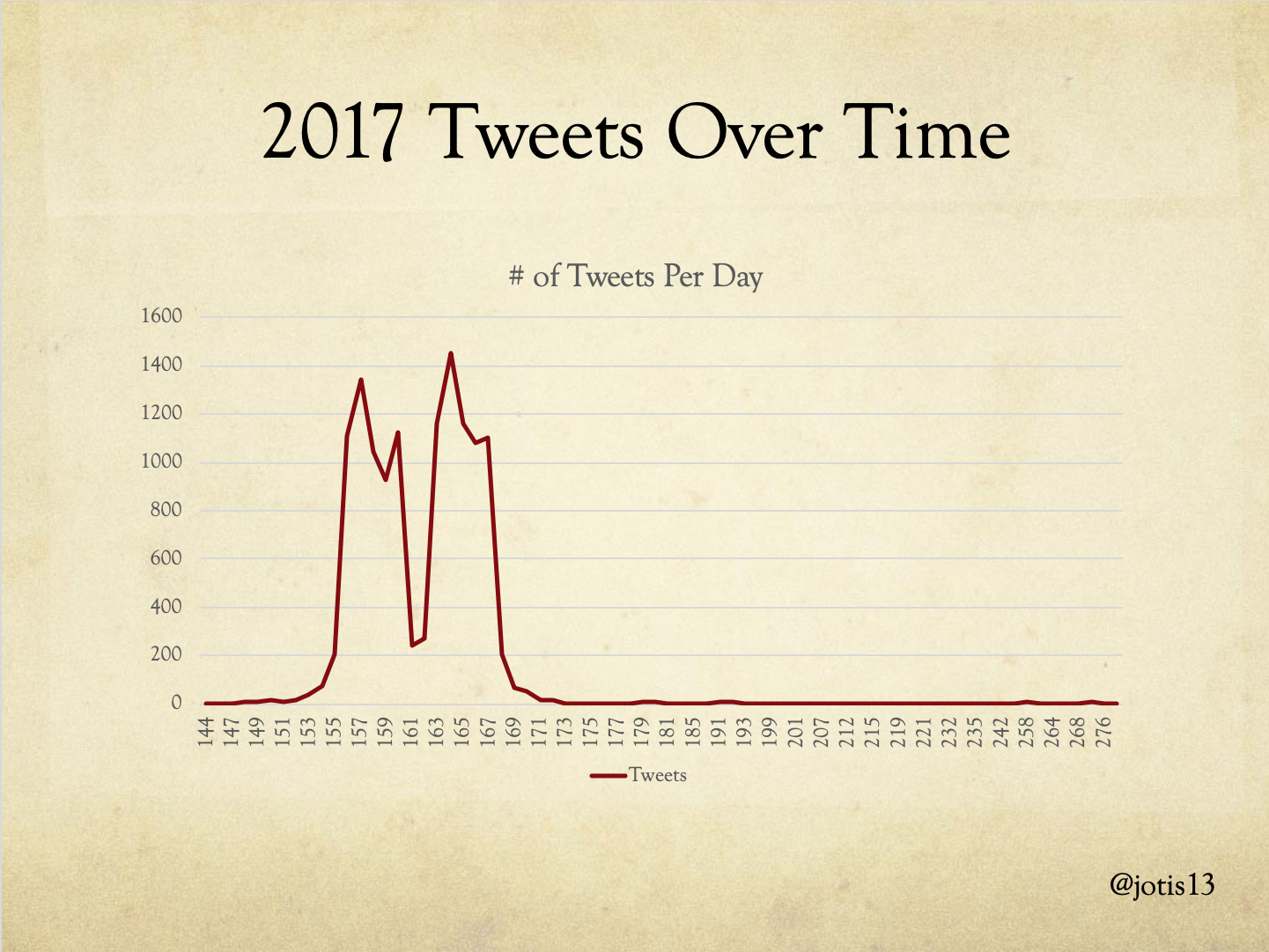
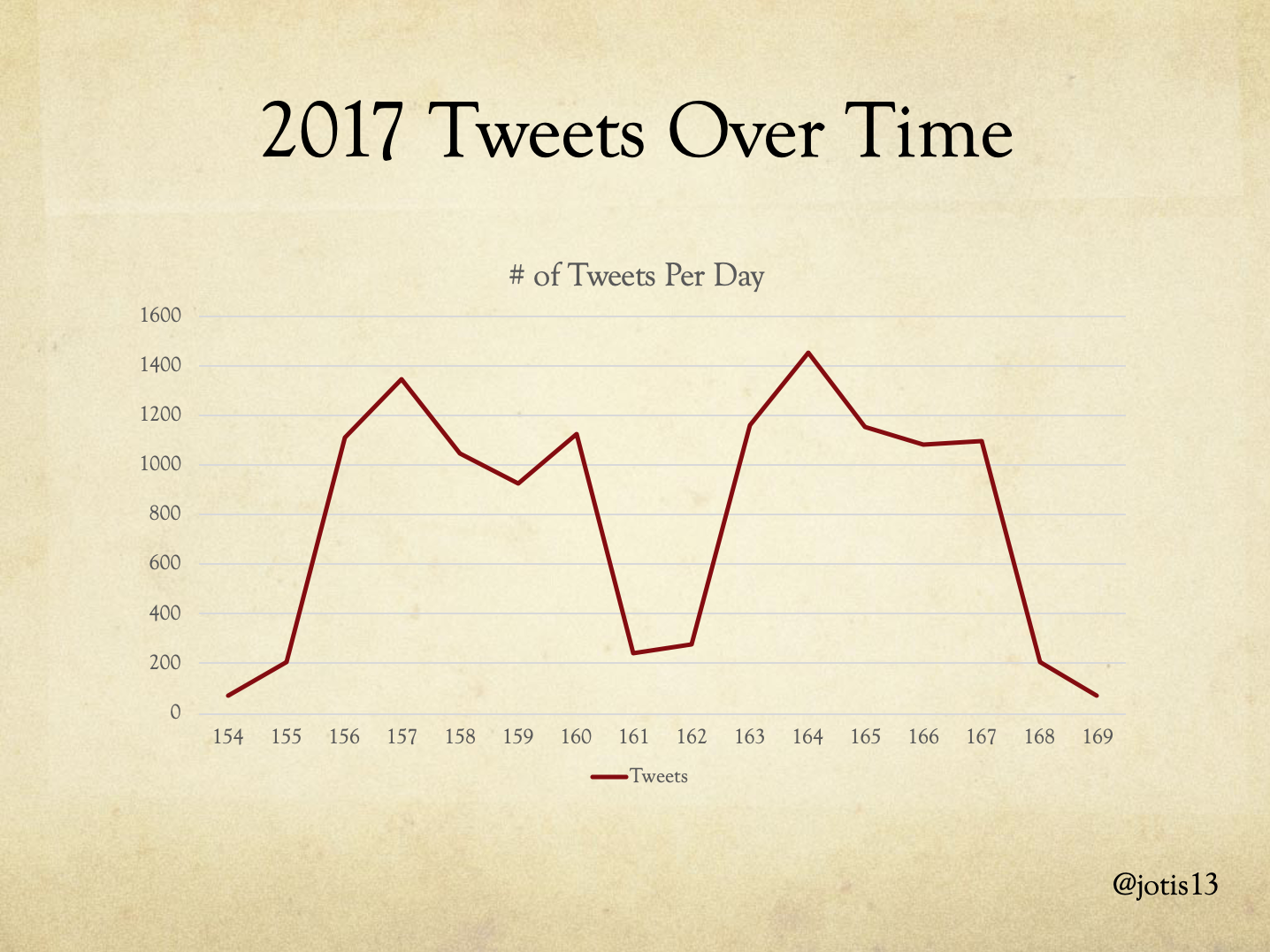
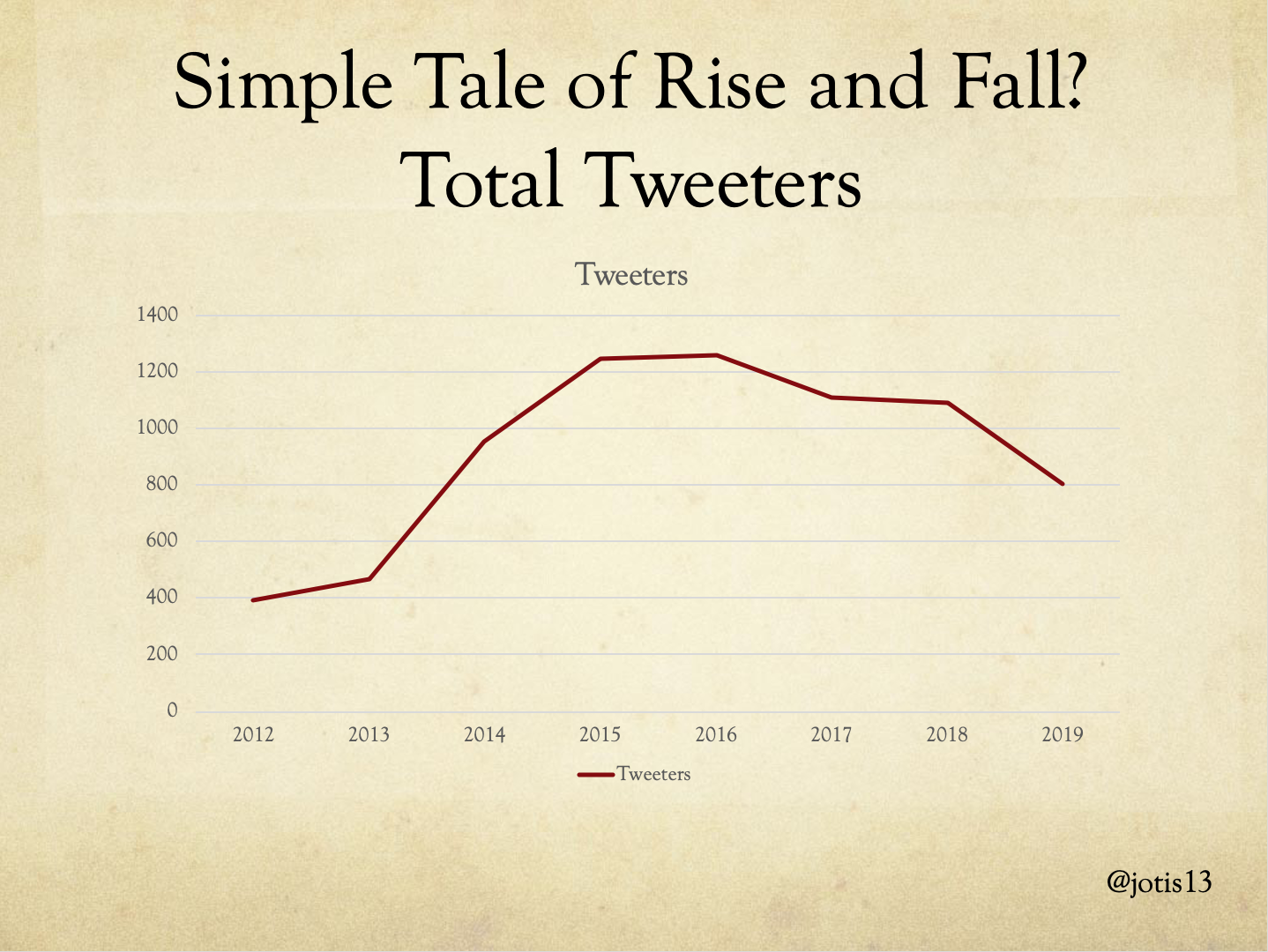
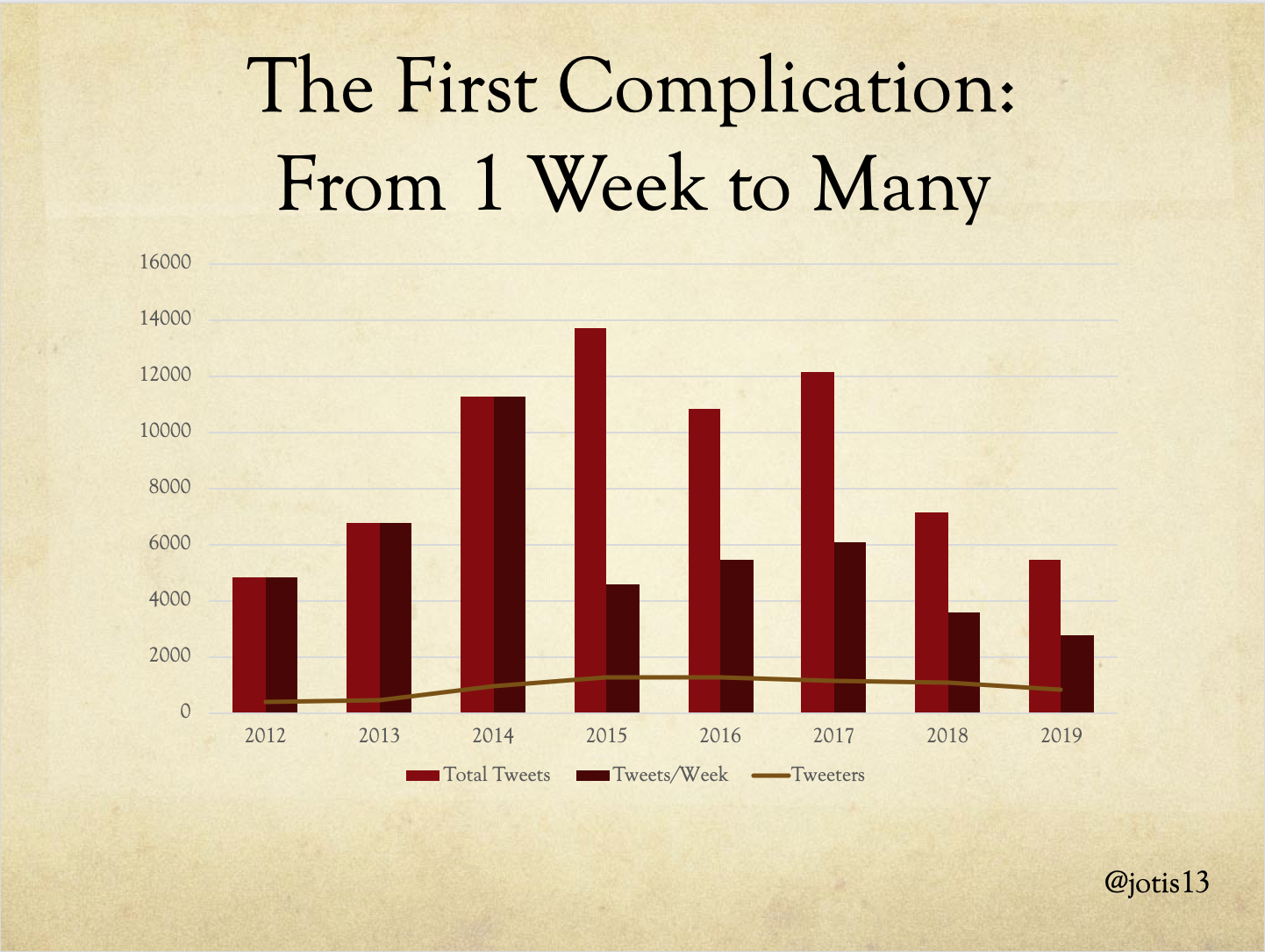
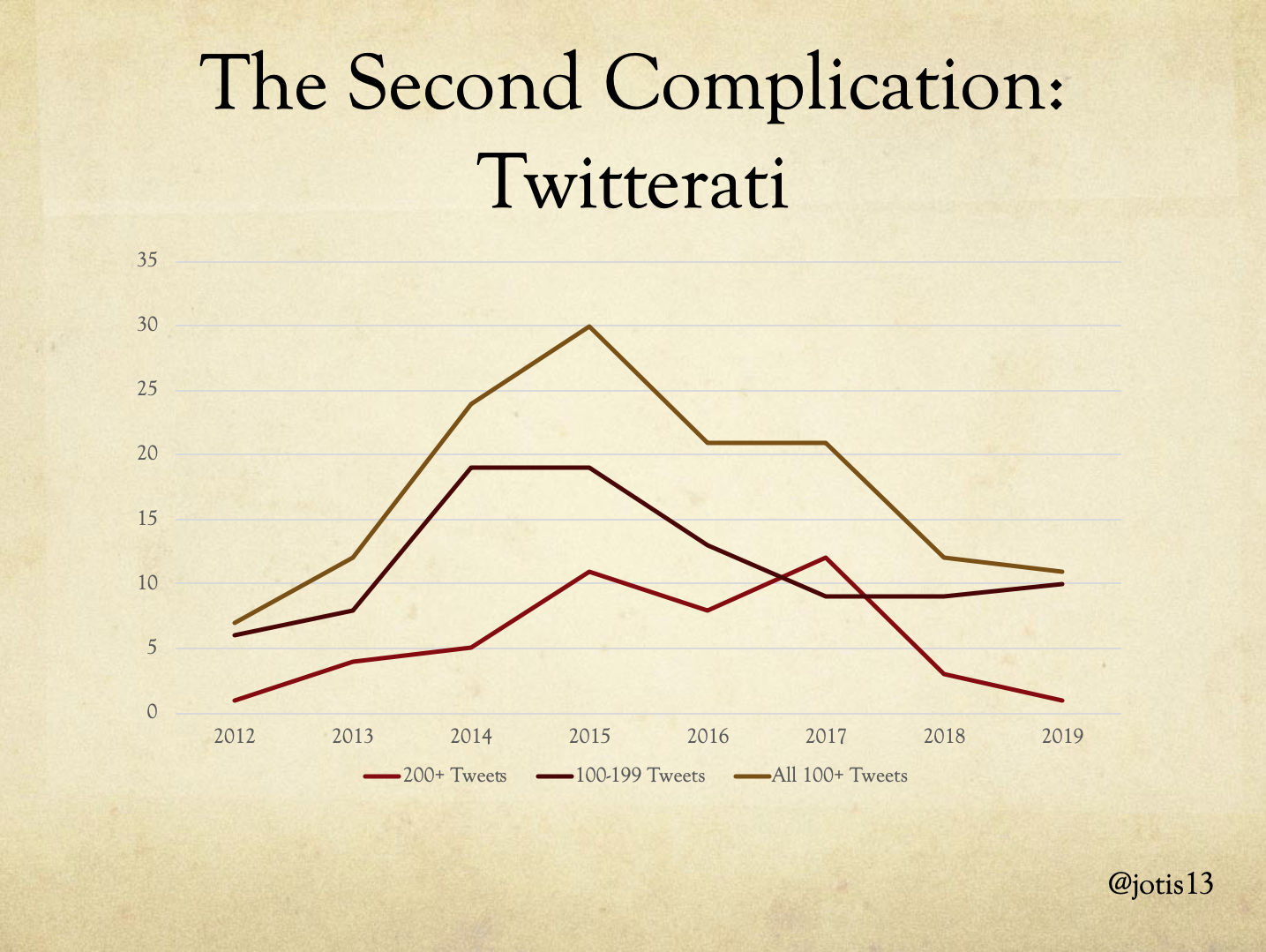
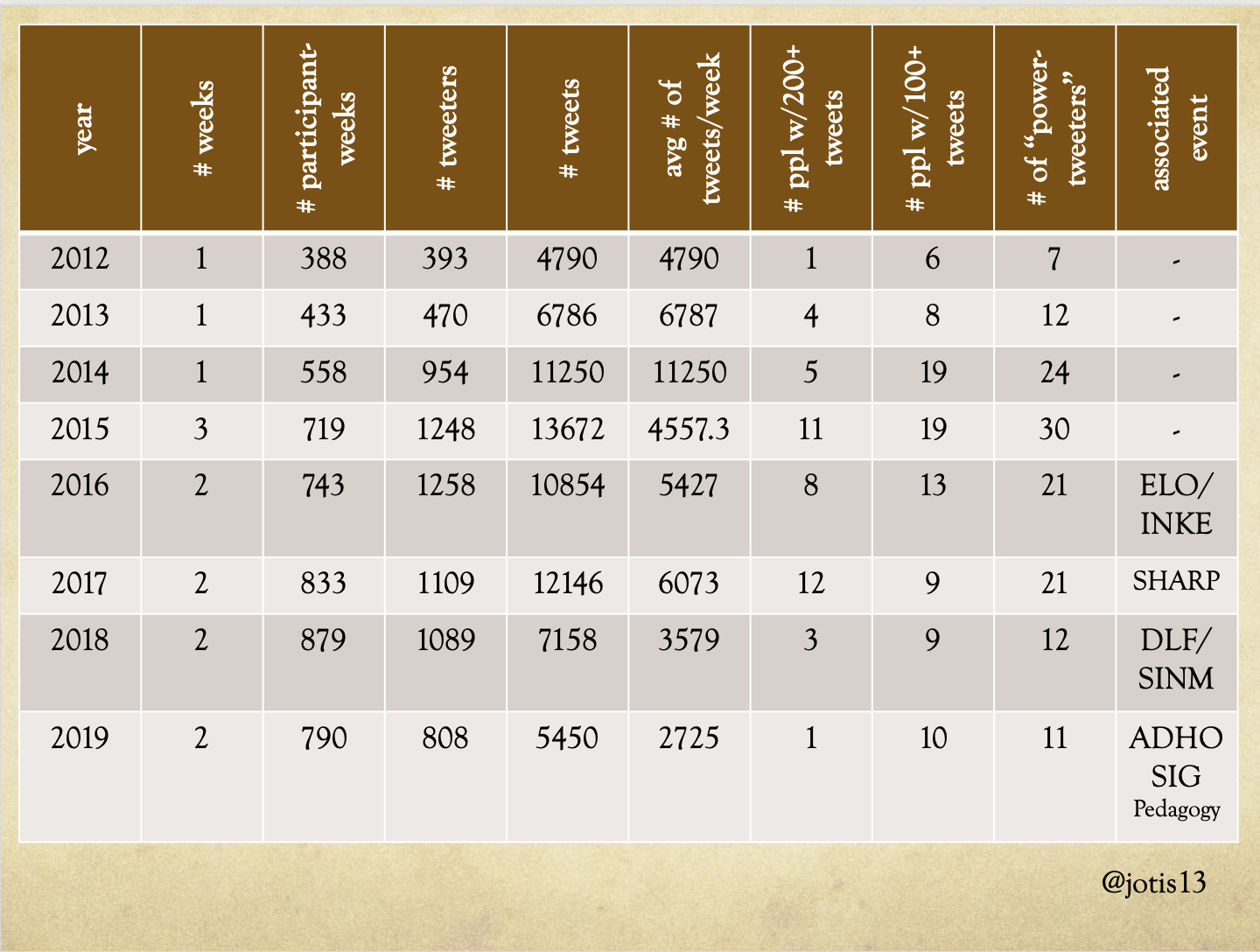
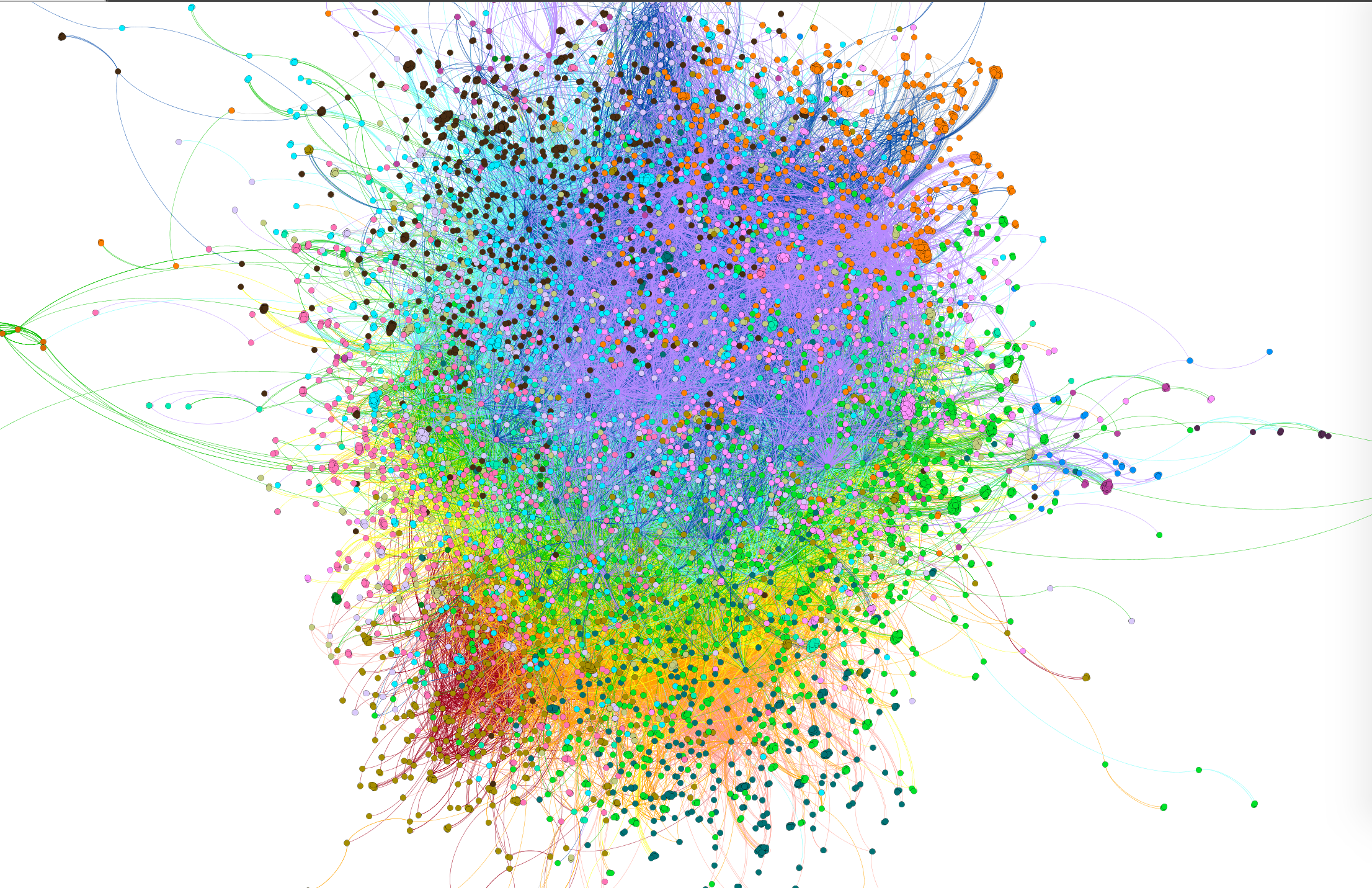


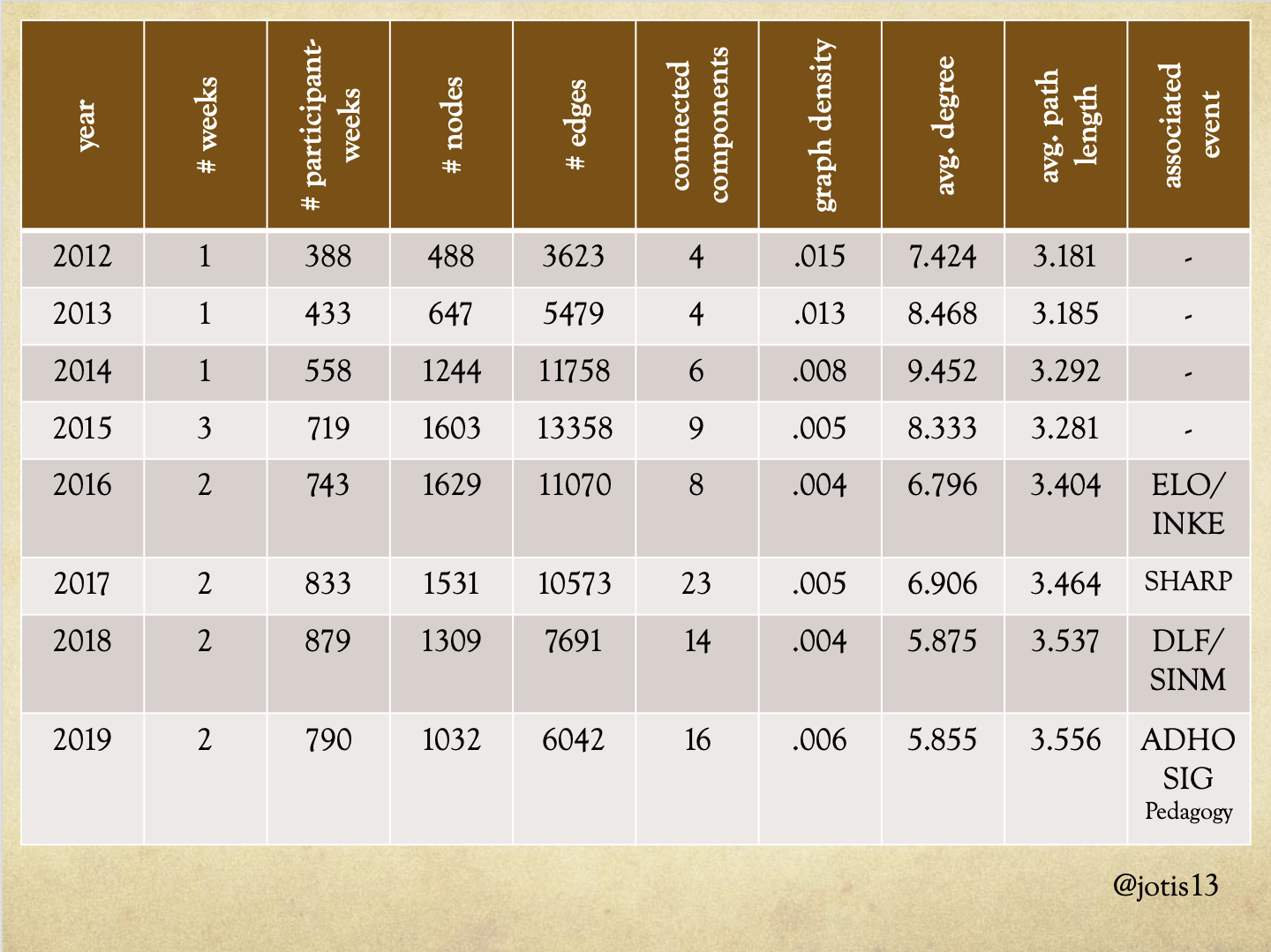

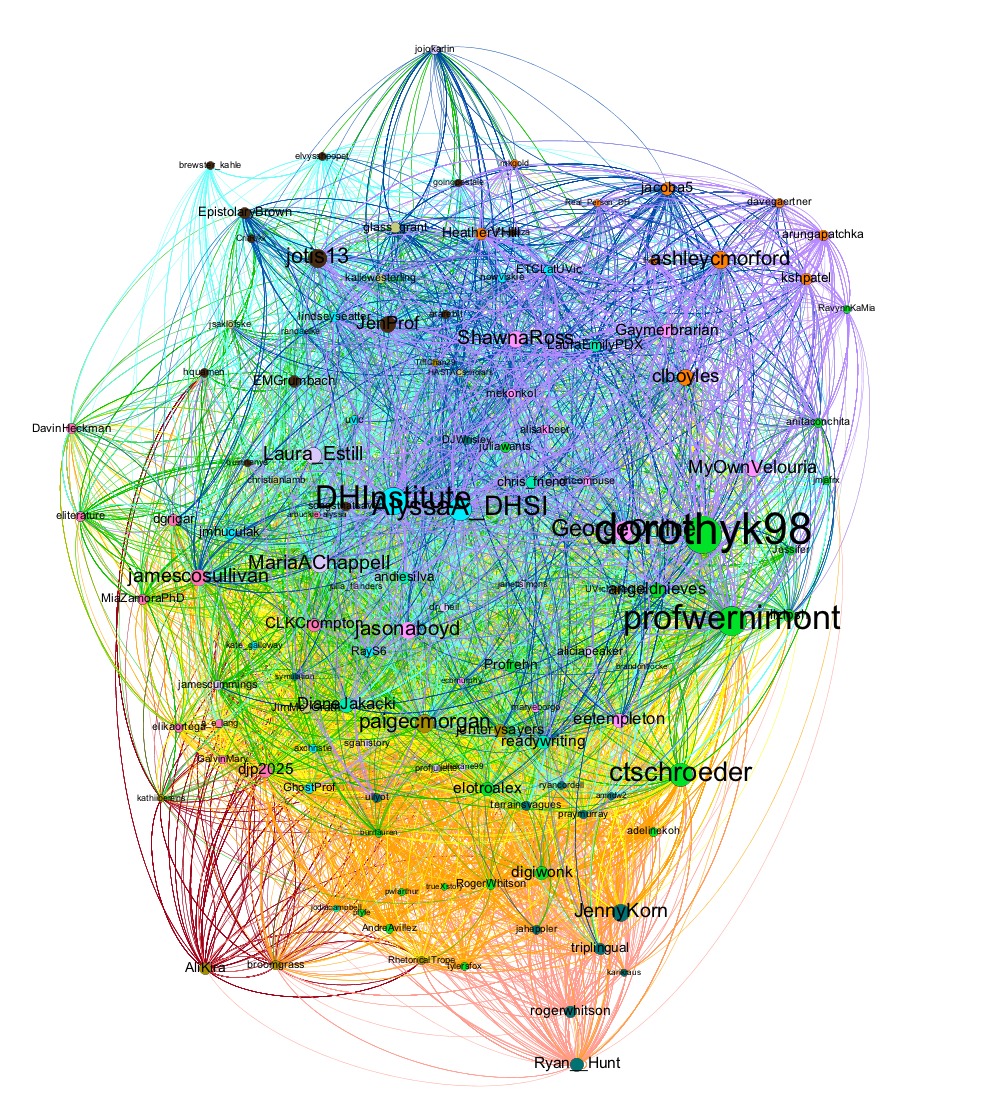





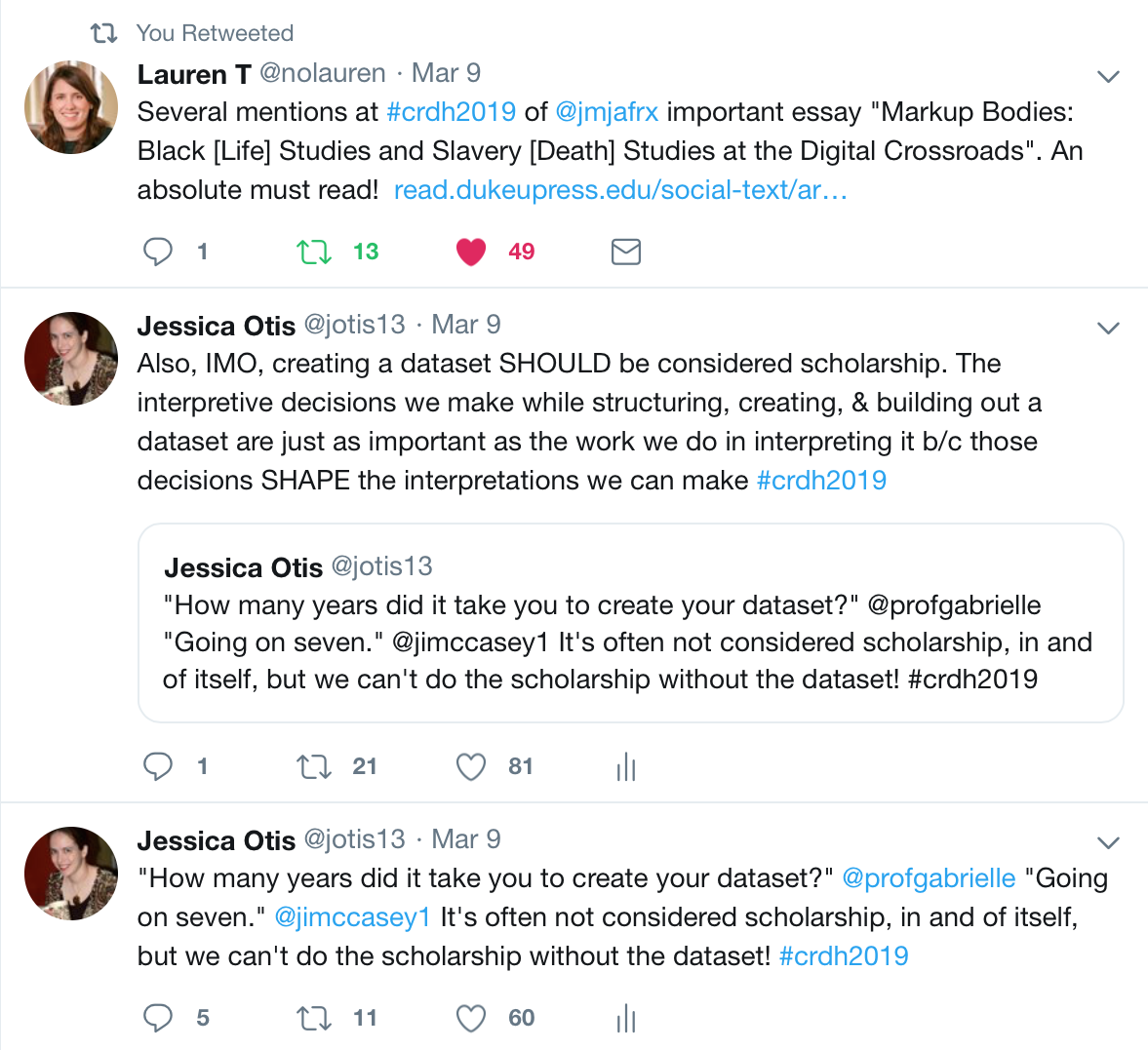
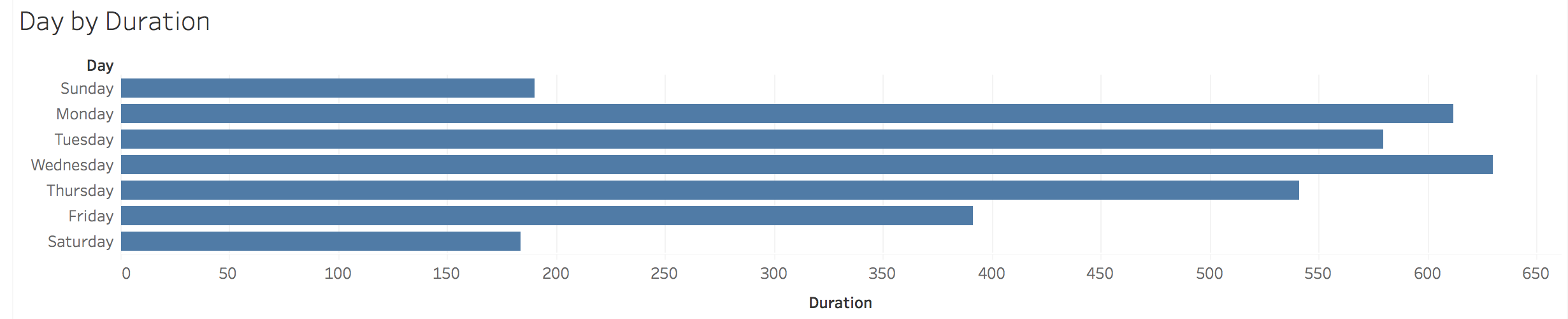
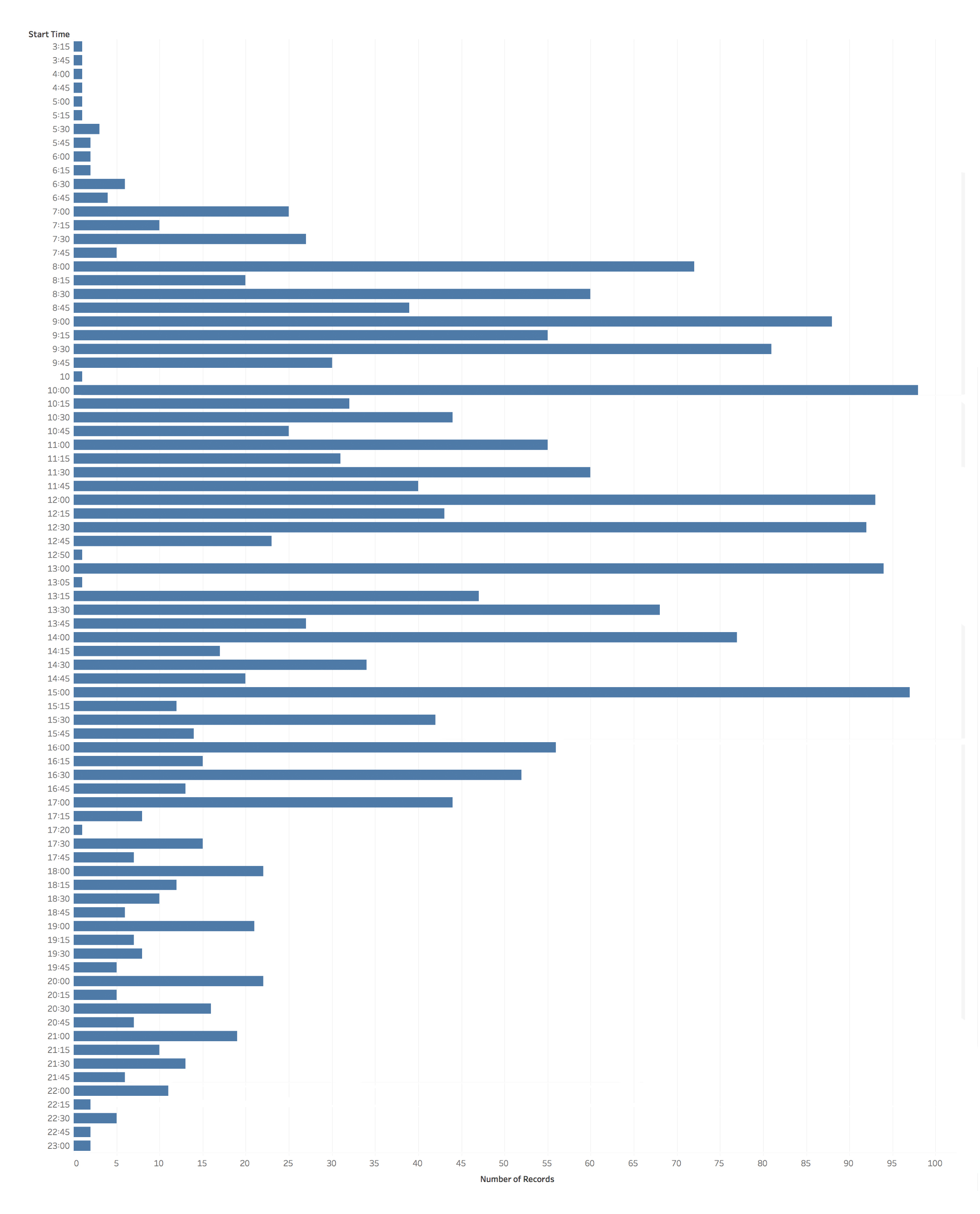
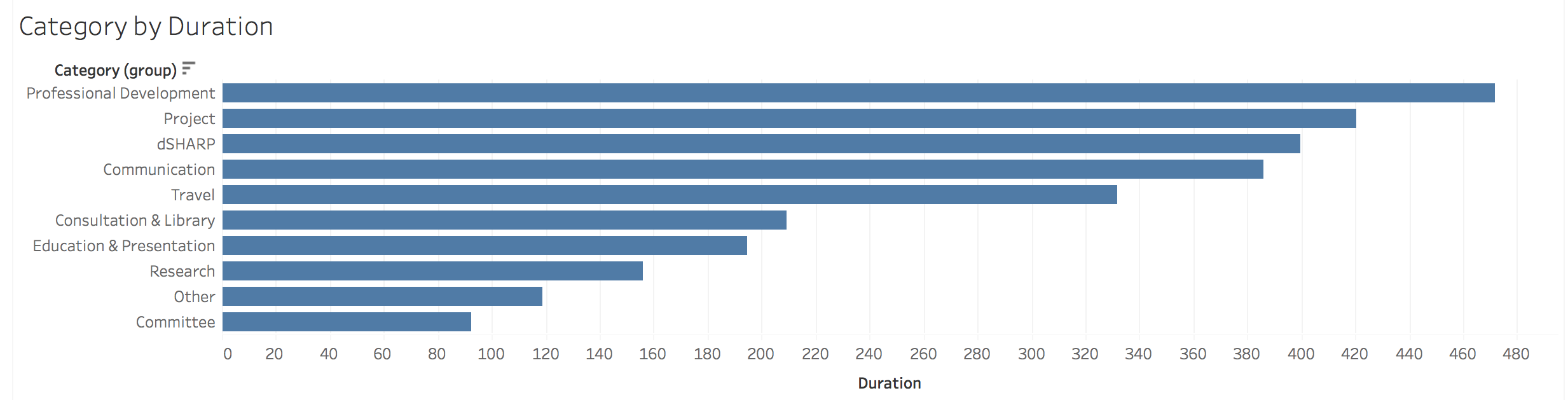
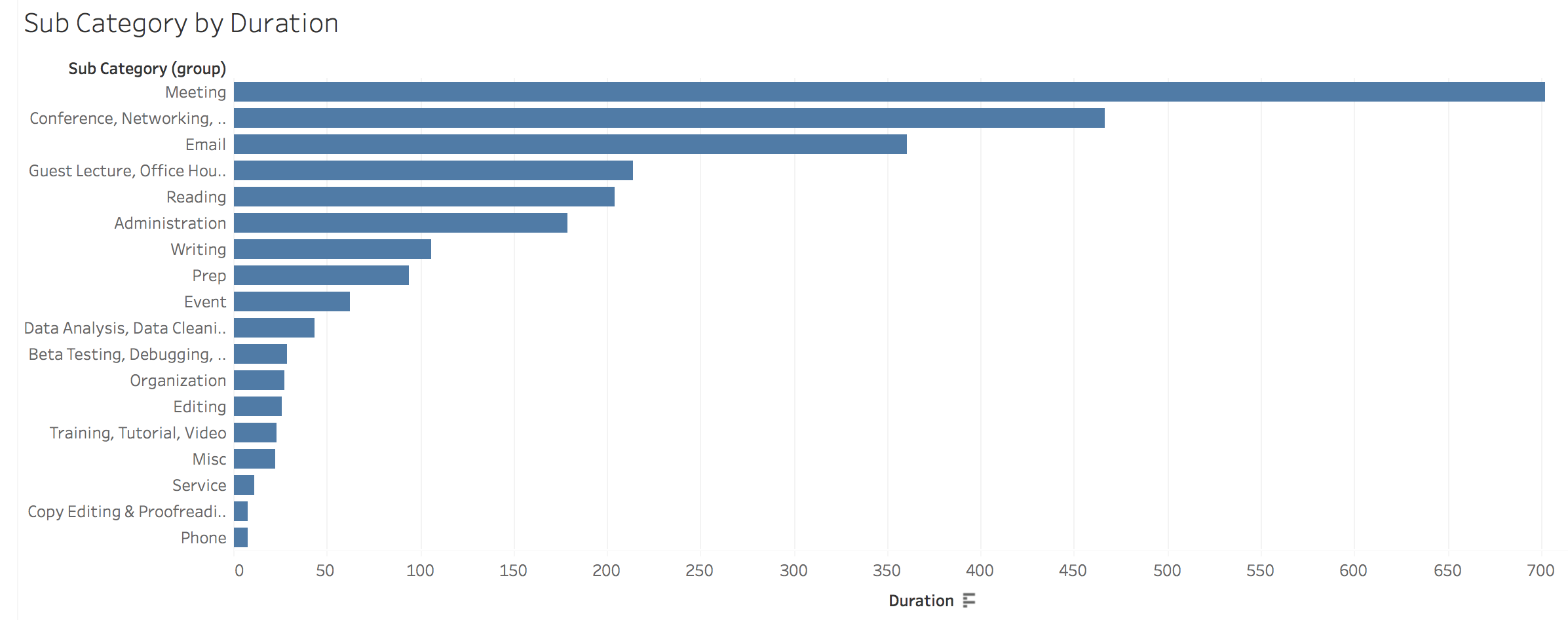
{kind=link}