NOTE: This is a lightly edited version of a talk I gave at the inaugural Chesapeake DH 2020 conference. My original intention was to wait to publish this until after June, to see if the trends I’d identified continued through this year’s DHSI. But the disruptions of the COVID-19 pandemic and the subsequent cancellation of pretty much everything have created enough of a rupture in the dataset that I’ve decided it is not advisable to extend my analysis past 2019.
TL;DR – people have wondered if DHSI Twitter is dying. I hypothesize, based on my analysis, that it is not dying so much as democratizing. First, we saw an explosion of Tweets as the network expanded to encompass more than a clique of early adopters (2014-6), then we saw a contraction as many Twitterati moved on or moved into the instructor corps (2017-9), leaving more “space” in the network for everyone else.
Rise and Fall of the DHSI Twitterati? A Longitudinal Analysis of the Digital Humanities Summer Institute Twitter Hashtags from 2012-2019
Digital humanists have been using Twitter to share their experiences at the annual Digital Humanities Summer Institute since at least 2009 and Twitter has become a staple of the DHSI experience, with official hashtags, organizer accounts, and a variety of prizes awarded to prolific or entertaining tweeters. But beginning in 2018 and again in 2019, people noted the decreasing volume of DHSI tweets, with one user speculating this might be “finally the turn away from twitter“. While it’s a bit soon to toll the death knell of DHSI Twitter—800 people wrote over 5000 tweets on the #dhsi19 hashtag—the absolute numbers do seem to tell a simple tale of an increasing number of people tweeting in the early part of the decade, which peaked in 2015 and 2016 and has been in decline ever since. However, these absolute numbers are a mask for series of more complicated patterns. This talk looks at DHSI Twitter from 2012 through 2019, examining the changing institutional circumstances of the institute, the expansion and fragmentation of the initial tweeting clique, and the role of power-tweeters (or “Twitterati”) in developing and sustaining DHSI Twitter.
I’m going to skip any detailed discussion of method and instead point you to my Twitter Methods Ur-Post if you’d like to read about data collection and processing. While I collected most of this data myself, I’d also like to give a shoutout to Jon Martin for collecting and sharing the first years in this dataset.
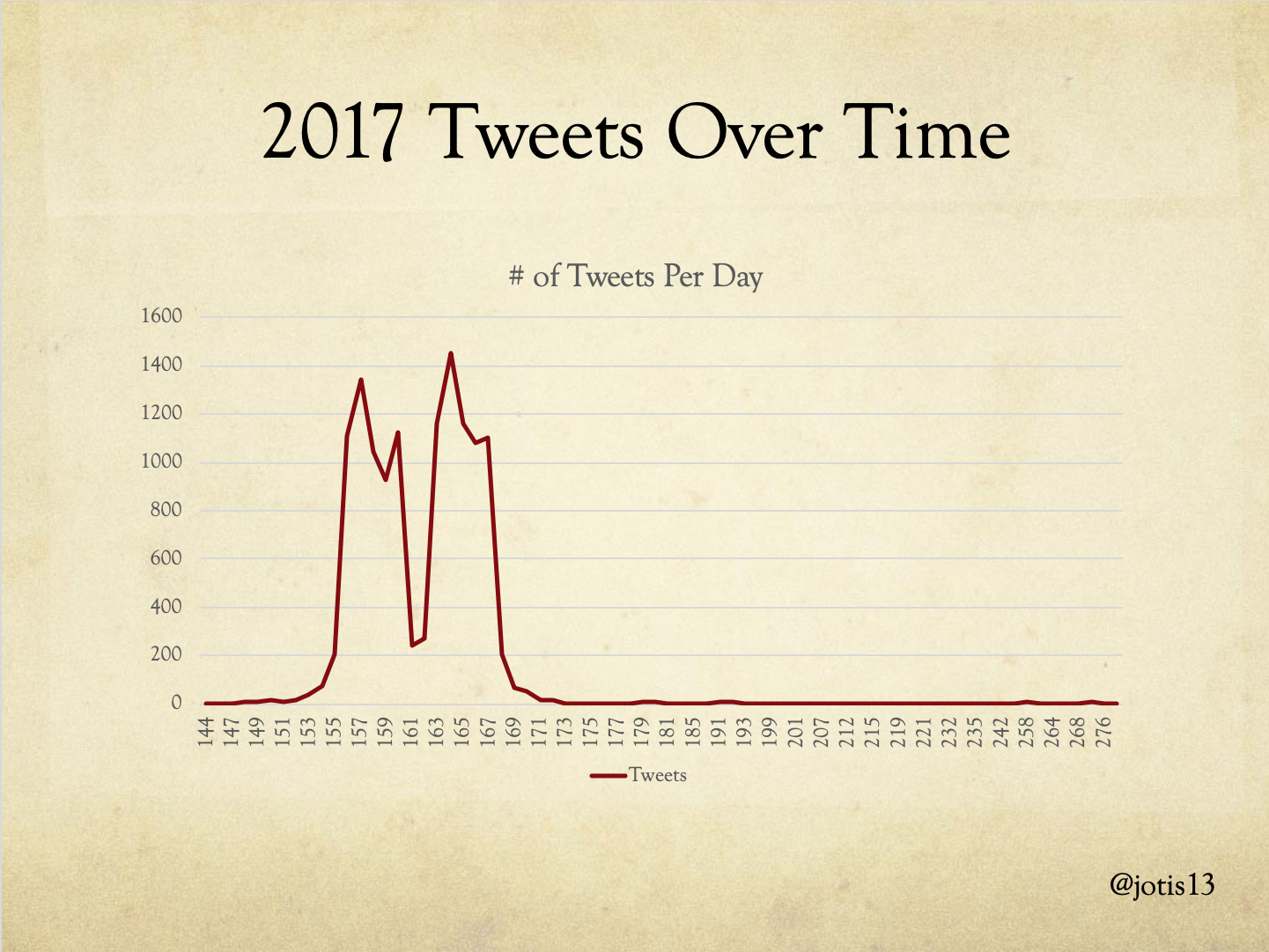
While I’ve collected Tweets over varying lengths of time, you can see from this graph the number of total DHSI tweets in 2017 that there is a sharp increase in number of tweets before the event and an equally sharp decline after the event, which made me comfortable cutting off long tail of tweets before and after DHSI without fear of missing too much.
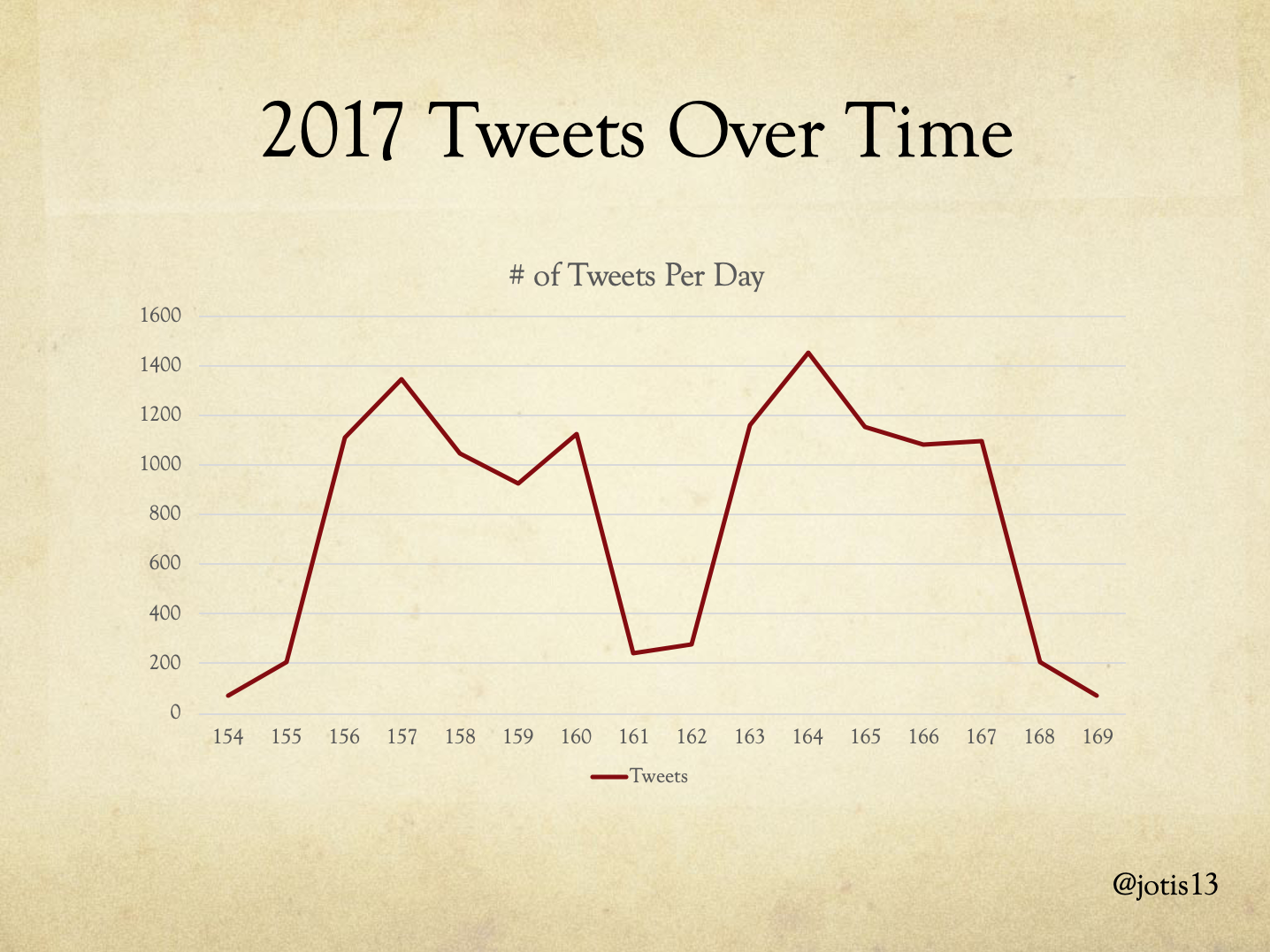
This is a visualization of +/- 2 days for 2017 so can see boundaries more clearly. In general, there is a pattern of a sharp uptick in the number of tweets in the first three days of each week – as people are traveling, then excited to be at DHSI – followed by a decrease over the next two days – as people are getting stuff done – with a bit of an uptick on the last day – as people give one last hurrah and declare the week was fun. There’s a sharp decrease over the weekend between the two weeks of DHSI, and an equally steep drop off at end of the entire event. Because of this, I feel comfortable focusing on the primary dates of each year’s DHSI, plus or minus 1 travel day (e.g. for 2017 this would be days 155 to 168 in the visualization above).
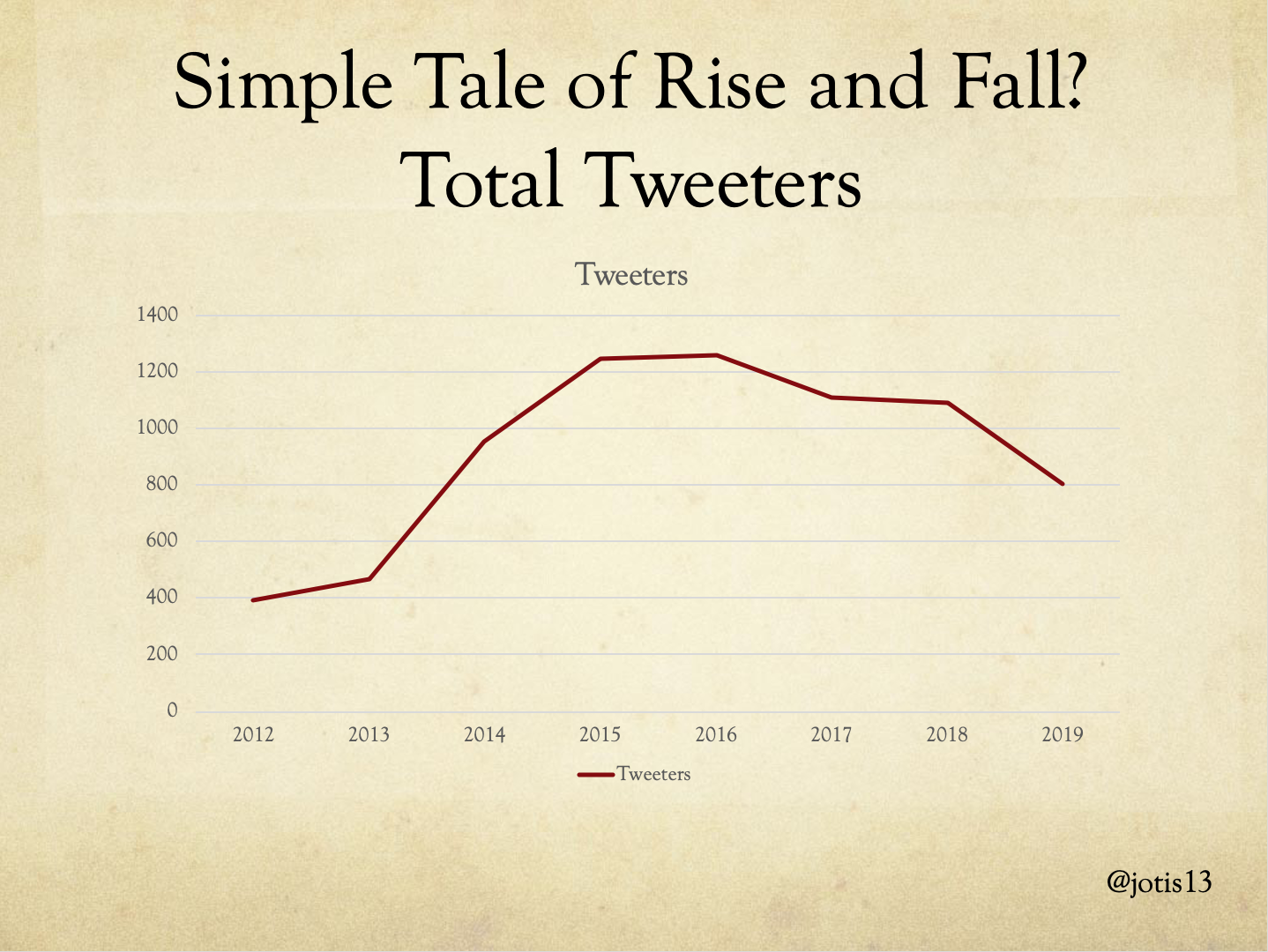
With those preliminaries out of the way, on to the fun stuff! If you look at the total number of people Tweeting at DHSI, concerns about decrease in Twitter activity seem correct if perhaps a little overblown. There’s a steady decline in 2017, 2018, with sharp drop off in 2019, less than any year since 2014, but who knows what 2020 would have looked like under other circumstances.
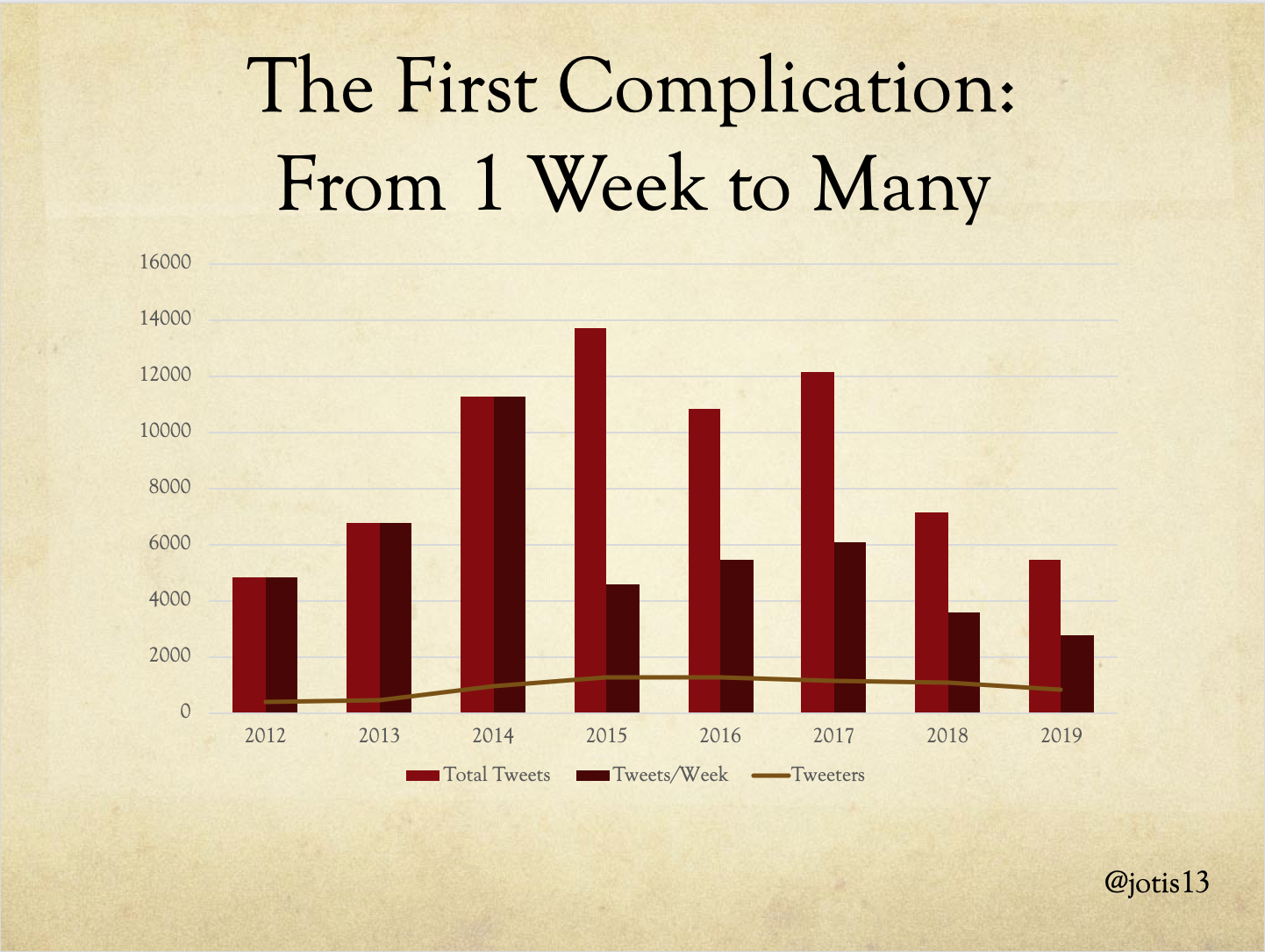
If we look at total number of Tweets, we get the same tale but perhaps more starkly. There is a peak in 2015, fewer Tweets in 2016, a slight recovery in 2017, and a sharp drop off in 2018 and 2019 which take us back down to the level of 2012. The sharp drop in 2018 all the more remarkable for the fact that total number of Tweeters was relatively steady from 2017 to 2018 – there were 20 fewer people but almost 5000 fewer Tweets!
But if we look at second bar in this chart – which is Tweets per week – we see the first complication in this simple narrative. In this column, the sharpest drop-off was actually between 2014 – the last year DHSI was 1 week only – and 2015 – when DHSI attempted to expand to 3 weeks in a grueling marathon. While this might logically have been expected to produce a threefold increase in Tweets, attendees report severe burnout and the institute was scaled back down to 2 weeks for all subsequent years. Indeed, burnout remains an issue and attendees are warned against it annually.
The total tweets per week recovered a bit in 2016 and 2017, but never reached heights of 2014. By that standard, DHSI Twitter has been dying since 2014.
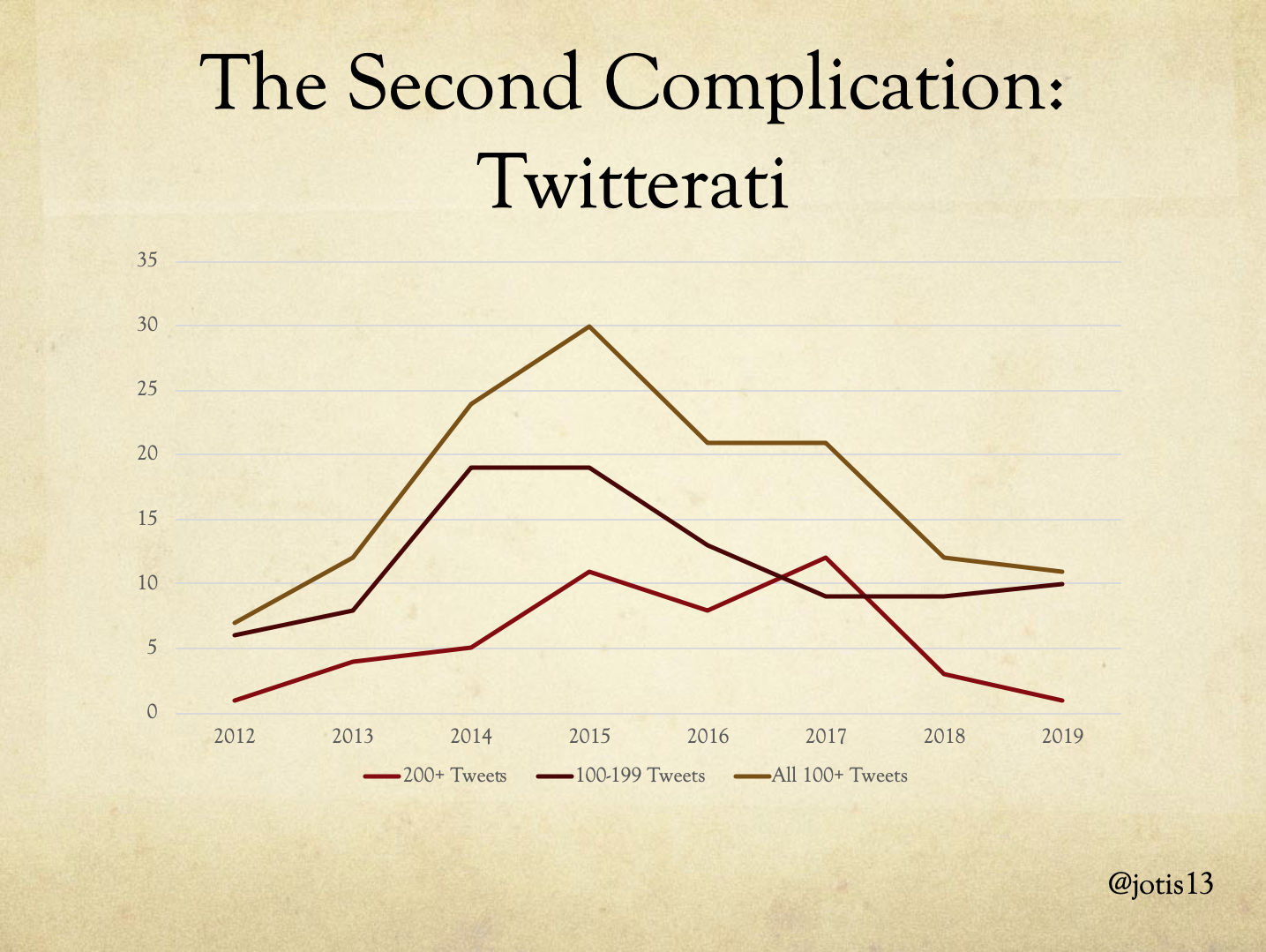
The second complication emerges when we look at a subset of the DHSI Tweeters, who I like to call Power-Tweeters or the Twitterati: people who Tweeted more than 100 times during any year of DHSI. To reach the status of Twitterati, a person has to produce 20+ Tweets a day if they only attend 5 days, or 9+ Tweets a day if they attend 2 weeks as well as the weekend in between. I’ve mapped here all the Twitterati, as well as subdivided the group into people with 200+ Tweets and people with 100-199 Tweets. (Note that, while 200 is the minimum number of Tweets to be in the first group, some people in that group are Tweeting 400, 600, even 817 times in a single DHSI.)
There aren’t many people who made it to 200 tweets when DHSI was only 1 week and we see the number of Twitterati in this category double in 2015, when the event went to 3 weeks followed by a decline in 2016 when the event was scaled back to 2 weeks. The number of Twitterati in the 100-199 saw its biggest increase a bit earlier, in 2014, and its biggest decrease also in 2016. But the number of Twitterati in this group have actually been holding steady since 2017, with even a slight increase into 2019.
This is in sharp contrast to the 200+ Twitterati. There was a spike in their numbers during 2017 followed by a huge drop off to 2018. In 2017, the twelve 200+ Twitterati were responsible for 3741 Tweets, but in 2018 the three 200+ Twitterati barely managed 781. In other words, 3000 of the 5000 Tweet difference between 2017 and 2018 can be accounted for by the decreased activity of this group. The trend continued into 2019, when only one person who managed to make it over 200 Tweets, and they barely squeaked over that line at 216.
So when it comes to the forces driving the overall number of DHSI Tweets, it seems clear that what we’re seeing is a drop in the number of Twitterati. While there’s also been a drop in the overall number of Tweeters, that seems more closely correlated to the drop in attendance at DHSI from 2018 to 2019.
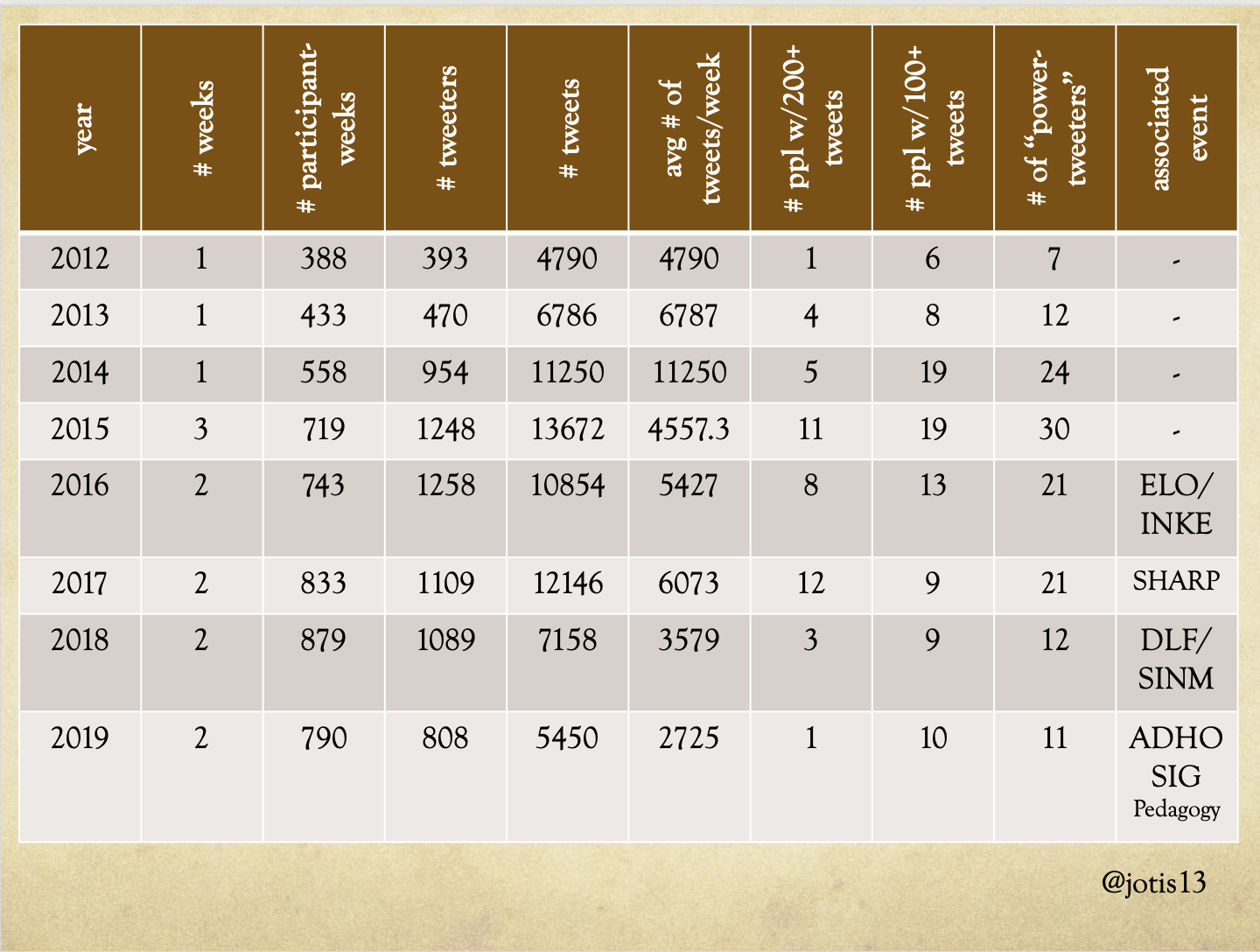
For those who are interested in the numbers, here’s the chart where you can can see how Twitterati correlate to number of Tweets and the sharp drop off in both for 2018 and 2019. It also shows the changing overall attendance numbers for DHSI. (Note that this column counts people twice if attended both weeks and uses public registration lists to determine attendance so it is not 100% accurate but close enough for our purposes.)
In this chart, you can also see a third possible complication that might be driving some of these numbers, which is the weekend conference. While the ADHO Sig Pedagogy and DLF events were great, those were also offshoots of a scholarly conference that happens at other times of year (the international DH conference and the DLF Forum, respectively). By contrast, 2017 was the year that SHARP held its one and only conference in conjunction with DHSI. And SHARP is another event that has historically been filled with Tweeters, with Twitter prizes and attendees who were paid to live-Tweet the conference in multiple languages. So a lot of what is driving the anomalous numbers in 2017 can actually be pinned on SHARP and SHARP’s Twitterati.
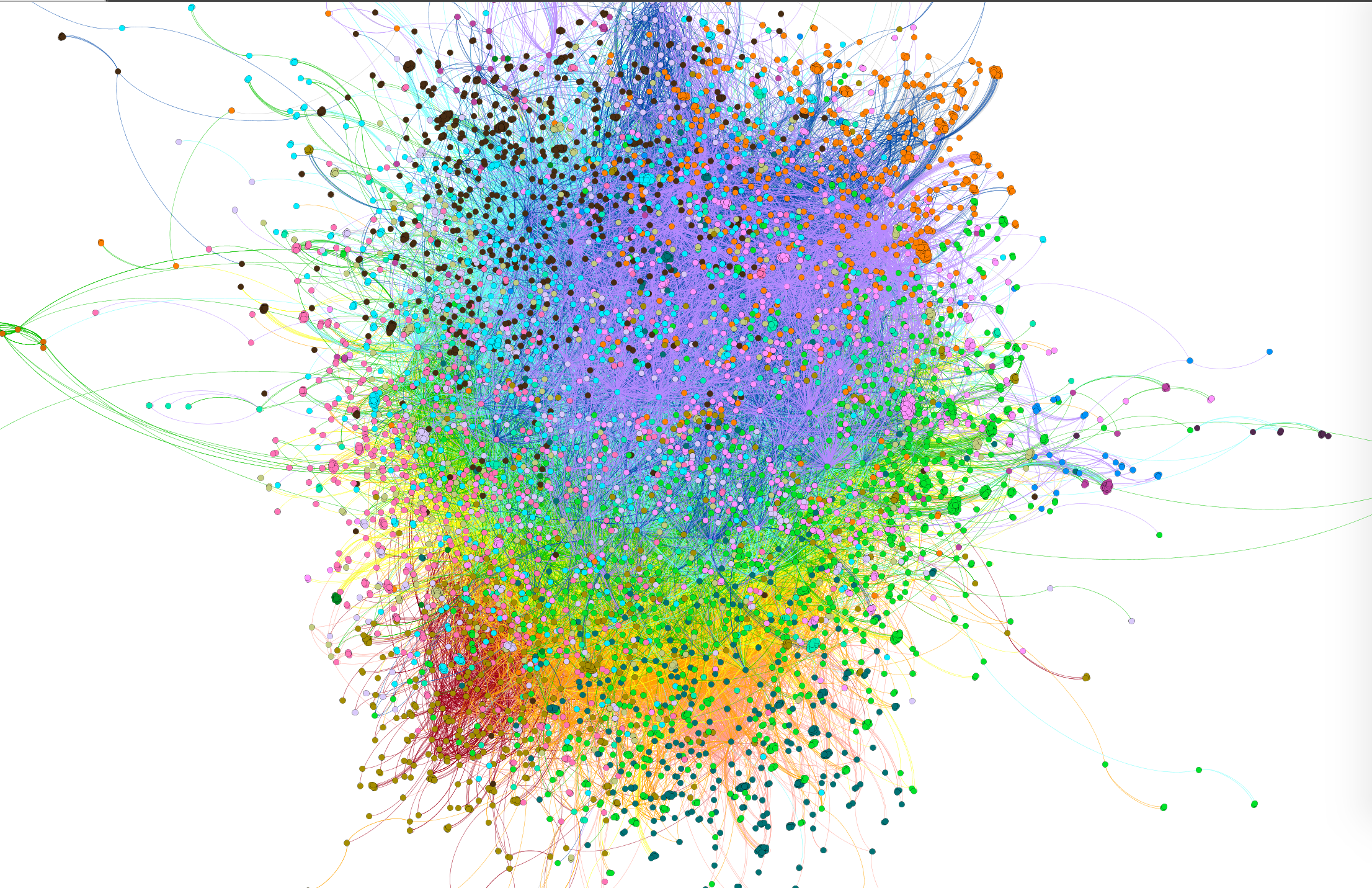
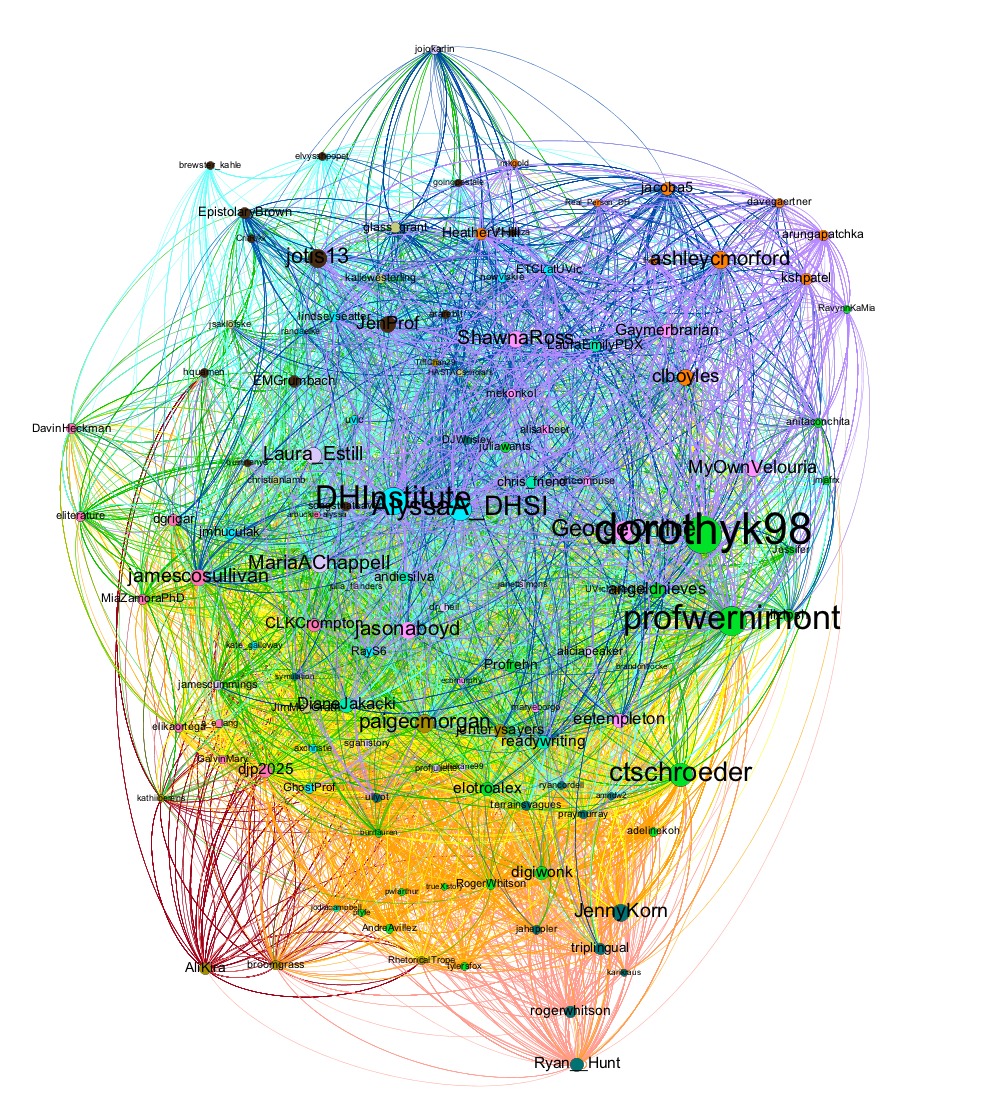
At this point, we’ve seen a few complications to our original, simple narrative, and hopefully I’ve intrigued you about the role of Twitterati at DHSI. Now it’s time to move onto… the super-network! Here is a visualization of the entire DHSI Twitter network from 2012-2019. It has 6539 nodes and 69594 edges (the red edges are 2012, orange is 2013, through to purple which are 2019 edges) in 43 connected components, of which 98.1% of nodes and 99.84% of edges are in the giant connected component.

And because network visualizations like this are always spaghetti monsters, here’s a slightly closer view, with nodes sized by degree – the number of times the person with that Twitter handle Tweeted or was Tweeted to/about – and colored by modularity class – algorithmically generated subnetworks. From here, you can already begin to see some of the Twitterati’s handles pop out, such as dorothyk98, profwernimont, DHInstitute, and AlyssaA_DHSI. I’m hanging out in the upper left hand corner. But this visualization also begins to let you see the sheer number of people who’ve attended and tweeted at DHSI over the years and how little the network has shifted over time. That is, there are no clear subnetworks, where each year emerges as an independent cluster of nodes.

You can see that a bit easier here, with each year separated out in the visualization. If you look closely, you can see there has been some drift over time:
- the red 2012 nodes are mostly to the bottom left of the combined visualization
- the pink 2013 nodes are to bottom right with some 2012 overlap
- the orange 2014 nodes are in the center and low bottom with significant 2013 overlap
- the yellow 2015 nodes are in the center with significant 2014 overlap
- the green 2016 nodes overlap most of 2015 and are a bit higher in the visualization
- the teal 2017 nodes overlap 2015 and 2016, but are a bit off to the left/top
- the dark blue 2018 nodes overlap 2017, but are a bit off to the right/top
- the purple 2019 nodes overlap most of 2015-8 and are a bit lower in the center
This is consistent with many people coming to DHSI for several years (mostly in a row) then stopping when no longer need training. Alternatively, they move into the instructor pool and stop Tweeting as much or stop Tweeting altogether because they’re too busy instructing.
Separating them out also lets you see the year Twitter really “caught on” was between 2013 and 2014 – the numbers of Tweeters and connections doubled, while the density of network halved. That is, this was no longer a tight clique of a few Tweeters but lots of people sharing the hashtag space.
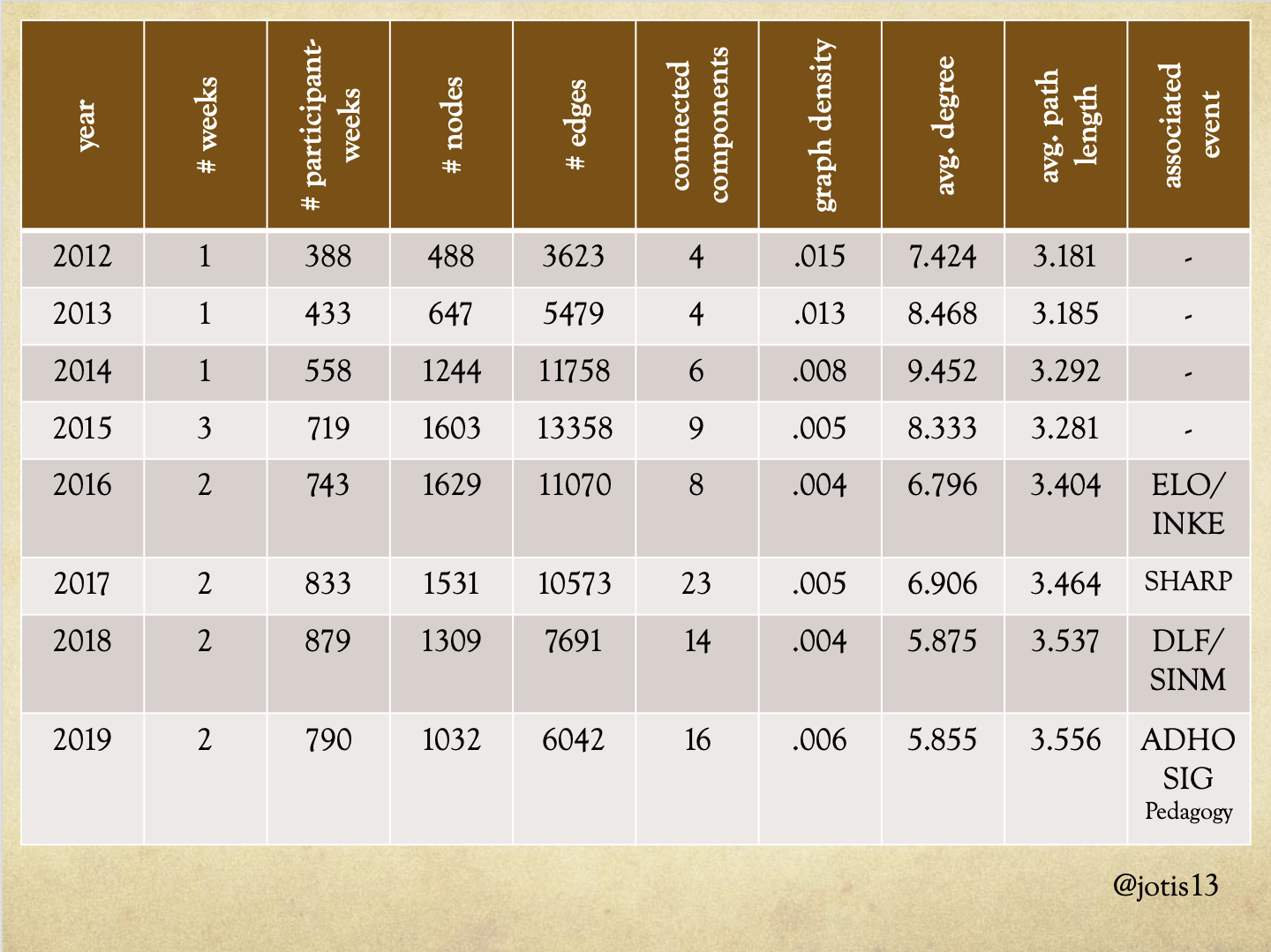
These are statistics on the network for each year’s DHSI. I know force-directed graphs are prettier than charts, but this chart lets us start to get into the meat of the network analysis, for example by showing you the changes I was just talking about between 2013 and 2014 more clearly. Far from 2014 being the year DHSI Twitter started to die, from a network analysis standpoint 2014 is the year DHSI Twitter finally caught on.
Moving forward in time to examine the two years where DHSI’s format changed dramatically – going from 1 to 3 to 2 weeks – we see the slow evolution of the Twitter network and how it only partially reflected those changes. There was a slight increase in Tweets/connections from 2014 to 2015, but it wasn’t proportional given the move from 1 to 3 weeks. We also see the graph density continue to decline, which makes sense: people attending only week 1 might not Tweet to those in week 2 or 3. The number of Tweeters increased from 2015 to 2016, and the number of overall connections decreased but again, it wasn’t proportional given the move from 3 to 2 weeks.
2017 stands out as an anomalous year in the network analysis as well. The number of Tweeters and connections decreased slightly from 2016 to 2017 but the number of connected components tripled. The average degree and density also increase a little, suggesting that SHARP attendees’ participation in the DHSI Twitter network both (slightly) increased the connectivity of its main connected component while at the same time fragmenting parts of it into far more numerous unconnected components.
In 2018, the number of Tweeters and connections both decreased markedly – as people were noticing on Twitter – but the number of Tweets actually declined at a much faster rate than number of connections. Again, this gives support to the hypothesis that these changers were driven by the Twitterati decreasing in numbers. People were still using Twitter to connect to each other, even if they weren’t producing as many tweets. Similarly, the number of Tweeters decreased markedly from 2018 to 2019 but the number of overall connections didn’t decrease in proportion to the decrease in the number of Tweets.
In other words, the DHSI Twitter network was still functioning as a network even though it seemed to have gone (relatively) radio silent.

To consider the importance of the Twitterati another way, I first visualized the network without them. For the purposes of the DHSI “super network,” I defined the Twitterati more generously as anyone who has tweeted over 200 times at all DHSIs combined (so anyone who’s been at 3 or more DHSIs might get into the Twitterati even if weren’t in the Twitterati for any 1 year). This cuts out a mere 2% of the nodes but a whopping 75% of the edges.
Another way to think of this is to note that 36% of the DHSI Twitter network consists of nodes that are connected to it by 1 Tweet and another 17% are connected by 2 Tweets. In other words, the VAST majority of people connected to DHSI hashtags are the weakest of possible ties – 1 and done. But these nodes share a quarter of the edges in the graph with each other and almost half the edges with the Twitterati.
By contrast, the Twitterati themselves consist of 123 nodes. That’s it. Only 2% of all nodes in the network have tweeted 200 or more times over this 8-year period, and amongst themselves they generate a bit under a third of all the edges.

So where does this leave us as I cram in the last few words before I’m out of time? There is a very, very small number of people responsible for the vast majority of DHSI tweets, and if we zoom in to the 1000+ Tweets club, we can see how truly small a handful of people this is. There are 18 of them (well, us). Thus just a few Twitterati attending or not attending in a year (or, if you know who many of these pepole are, just a few Twitterati moving into the instructor corp!) can have an outsized impact on the network.
BUT ALSO, if you will allow me to return to an earlier visualization…
…it’s possible what we have been seeing in 2018 and 2019 is not the demise of DHSI Twitter so much as the democratization of DHSI Twitter. Each year, there have been fewer and fewer Twitterati dominating the conversations, making space for everyone else. And that is as beautiful a network as the super-network I started with. Thank you.